Keeping the full picture - additional context in embedded chunks

When working with vector search on large documents, chunking is a usual part of the process. Instead of generating a single embedding for an entire report, book, or document, the content is split into smaller pieces, and each chunk receives its own embedding. Besides helping fit large documents within model limits, chunking allows vector search to retrieve the specific section that contains the answer rather than treating the entire document as a single match.
Most of the time, this works exactly as intended. The problem appears when important context lives in one part of a document, while the information you actually want lives only in a few chunks.
Imagine an article about RavenDB. Early on, it introduces vector search and explains what it is. Twenty pages later, a chunk mentions embeddings, similarity search, and retrieval performance. A human reader immediately knows the discussion is still about vector search because they have the entire document in their head. However, a single vectorized chunk is not that knowledgeable.
That missing context matters because embeddings are generated from the contents of each chunk. If the information that explains what a chunk is about appears elsewhere in the document, it never makes it into this chunk's embedding. The context still exists in the source document, but it was left behind when the document was split apart.
Once we realized that, the next question was simple: can we keep some of that document-level context while still getting all the benefits of chunking?
Context Prefix
To handle this problem, RavenDB 7.2.3 introduced the withContextPrefix(...) method. This allows you to add document-level context to every chunk before it is sent to the embedding model. As a result, each chunk carries information that might otherwise be lost when the original document is split into smaller pieces.
The context prefix can be generated from the document itself. In practice, it is often built from metadata such as a title, company name, category, or other identifying information that helps describe the document. Every chunk generated from that document receives the same prefix, ensuring that even small fragments retain some awareness of what they are describing.
There is one trade-off to keep in mind. The context prefix is included in the text sent to the embedding model, so it consumes part of the chunk's token budget. Every token allocated to the prefix is one less token available for the original document content.
In practice
Using withContextPrefix(...) requires only a single additional method call. Here is the baseline version that generates embeddings from paragraph chunks:
// Without context prefix - baseline
embeddings.generate({
Embedding: text.splitParagraphs(this.Text, 512)
});
And here is the same script with a context prefix applied:
// With context prefix - the company name from this.Title
// is added to every chunk before embedding
embeddings.generate({
Embedding: text.splitParagraphs(this.Text, 512).withContextPrefix(this.Title)
});
Or you can add a context prefix to all properties at once. This prefix will be applied to every chunk unless a property defines its own context prefix. In that case, the per-property context prefix has priority and overrides the task-wide setting:
embeddings.generate({
ContentEmbedding: text.splitParagraphs(this.Content, 512).withContextPrefix(this.Category),
DescriptionEmbedding: text.splitParagraphs(this.Description, 512),
FAQEmbedding: text.splitParagraphs(this.FAQ, 512)
}).withContextPrefix(this.Title);
The feature is implemented as a chained method on the chunker's output, making it easy to add to an existing embedding-generation task script. The argument is simply a string, which means it can be a literal value, a document field such as this.Title, or any string produced by the JavaScript engine.
The prefix is applied at the document level. Every chunk generated from a given document receives the same context prefix, while chunks from other documents can receive a different one. This makes it straightforward to inject information such as document titles, company names, categories, or other metadata into the embedding process without changing the chunking strategy itself.
How we tested it
Before looking at the results, it is worth understanding what exactly we measured.
Test corpus
Our test corpus consisted of 30 SEC 10-K filings from large publicly traded companies. These annual reports are often hundreds of pages long and contain a mixture of financial results, business descriptions, risk disclosures, and operational details. To keep the benchmark practical for local runs, we limited each document to approximately 150,000 characters (around 30,000 tokens). We are also using a relatively small number of documents (30) to keep it local-friendly. Each document contained two fields: a Title holding the company's legal name and a Text field containing the cleaned filing content.
Embedding tasks
We created two embedding tasks over the same corpus. The first, sec-nocontext, generated embeddings from chunks exactly as they appeared in the document. The second, sec-withcontext, generated the same chunks but added the company name from the document title to each chunk before embedding. Apart from the context prefix, everything else remained identical.
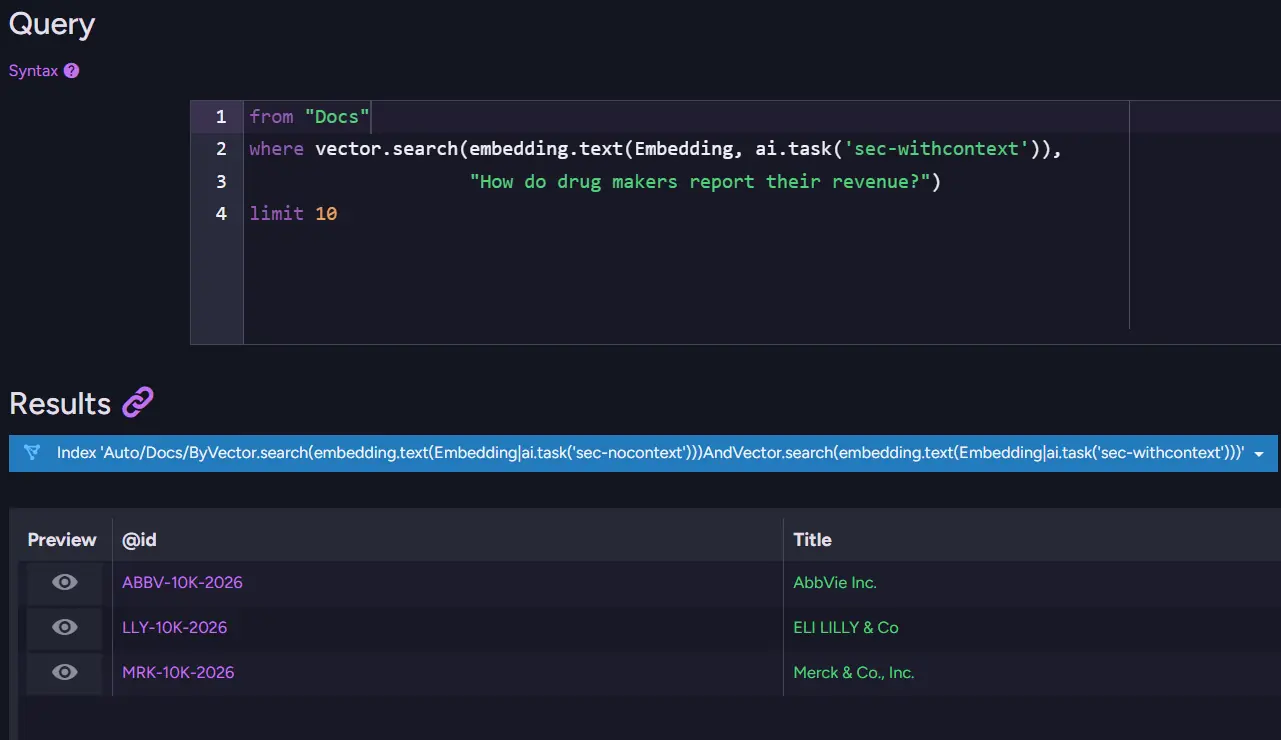
To evaluate both approaches, we prepared two separate query sets. The first contained roughly 150 per-company queries, each targeting a specific company. A typical example would be "What does Apple Inc. report about its revenue?" In this scenario, there is usually a single correct document. The second set contained roughly 50 category-level queries, such as "How do drug makers report their revenue?" Here, multiple documents can be relevant at the same time, for example, the filings from Johnson & Johnson, Merck, Eli Lilly, and AbbVie.
Query sets and metrics
Both embedding tasks used the same embedding model: qwen3-embedding:0.6b running locally through Ollama. The model was chosen because it is modern, lightweight, and can run comfortably on consumer hardware. The use of the context prefix was the only variable.
For each query, we retrieved up to ten results and measured three standard information-retrieval metrics:
- Precision measures how many of the returned documents were actually relevant.
- Recall measures how many of the relevant documents were successfully found.
- F1 combines both into a single score and drops sharply when either precision or recall suffers.
We report all three metrics because the most interesting part of the benchmark is not whether the prefix helps, but how it changes the balance between finding more results and finding the right results.
Results
The result is clear: adding a context prefix improved the F1 score across both query sets. The details, however, reveal a more nuanced story.
For per-company queries, the context prefix delivered a clear win across every metric we measured. Precision increased from 0.393 to 0.885, a gain of 125.4%. Recall improved from 0.887 to 0.940, an increase of 6.0%. Combined, these improvements pushed F1 from 0.486 to 0.900, an 85.1% increase.
| Metric | no-context | with-context | delta |
|---|---|---|---|
| Precision | 0.393 | 0.885 | +125.4% |
| Recall | 0.887 | 0.940 | +6.0% |
| F1 | 0.486 | 0.900 | +85.1% |
If someone searches for "What does Apple Inc. report about its revenue?", adding "Apple Inc." to every chunk from Apple's filing gives the embedding model a constant reminder of which document that chunk belongs to. The result is less confusion and far fewer irrelevant matches. Admittedly, this is not the most challenging example, since both the query and the chunks contain the company name.
One query from the benchmark illustrates the point clearly. When we searched for "What does Apple Inc. report about its revenue?", the no-context index returned four documents: Microsoft, Apple, Meta, and Adobe. Apple was there, but it wasn't even ranked first.
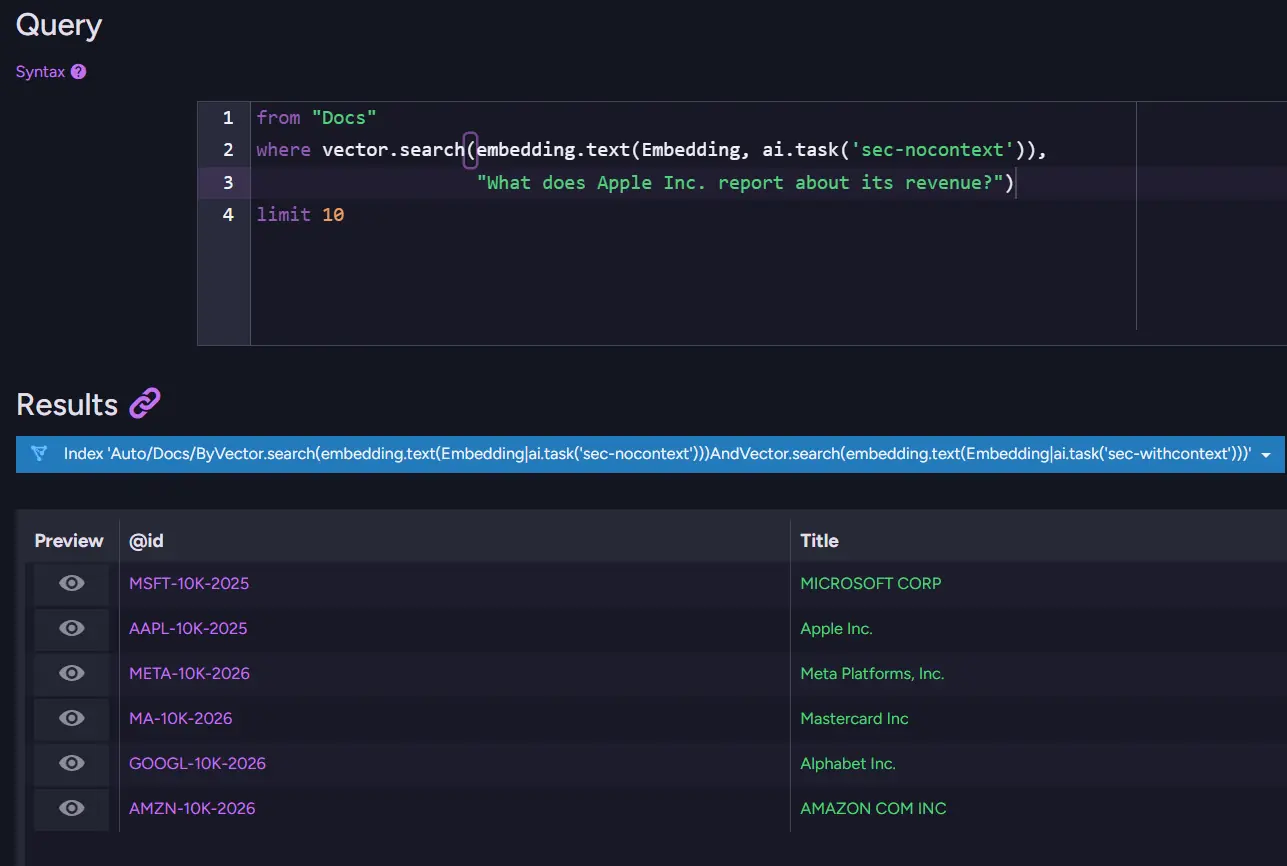
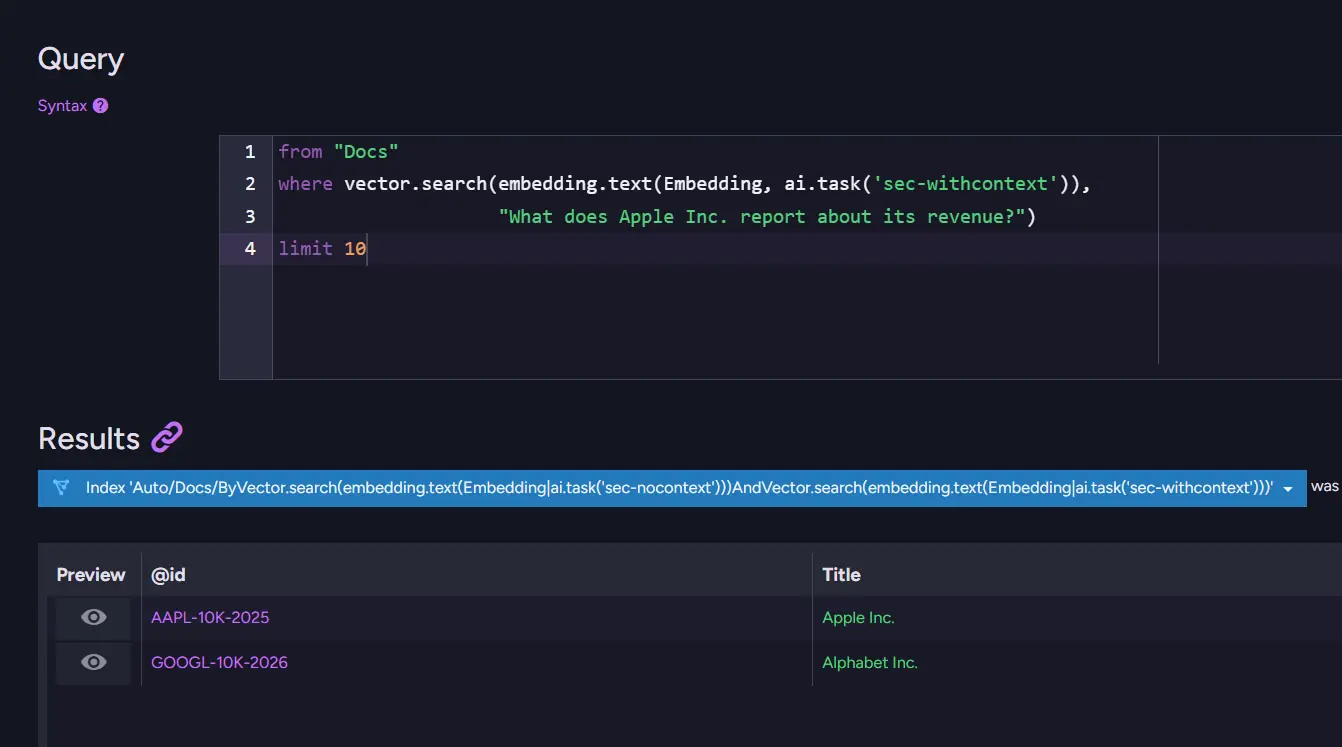
With the context prefix enabled, the result set shrank to two documents, and Apple immediately moved to the top spot. Fewer results, fewer mistakes, and a much stronger signal that we found the right document.
Category queries tell a different story.
| Metric | no-context | with-context | delta |
|---|---|---|---|
| Precision | 0.447 | 0.610 | +36.5% |
| Recall | 0.883 | 0.752 | -14.9% |
| F1 | 0.555 | 0.629 | +13.4% |
The good news is that F1 still improved, climbing from 0.555 to 0.629. Precision also increased significantly, from 0.447 to 0.610. If we stopped there, the story would be simple: add context, get better results.
But recall instead of going up, dropped from 0.883 to 0.752. At first glance, that looks strange. We added more information to every chunk. Why would the system find fewer relevant documents?
Looking at individual queries made the pattern pretty obvious. The context prefix made the search more confident. Result sets became smaller and cleaner. Documents that barely matched stopped appearing. Most of the time, that was exactly what we wanted. Occasionally, though, one of the genuinely relevant documents disappeared as well.
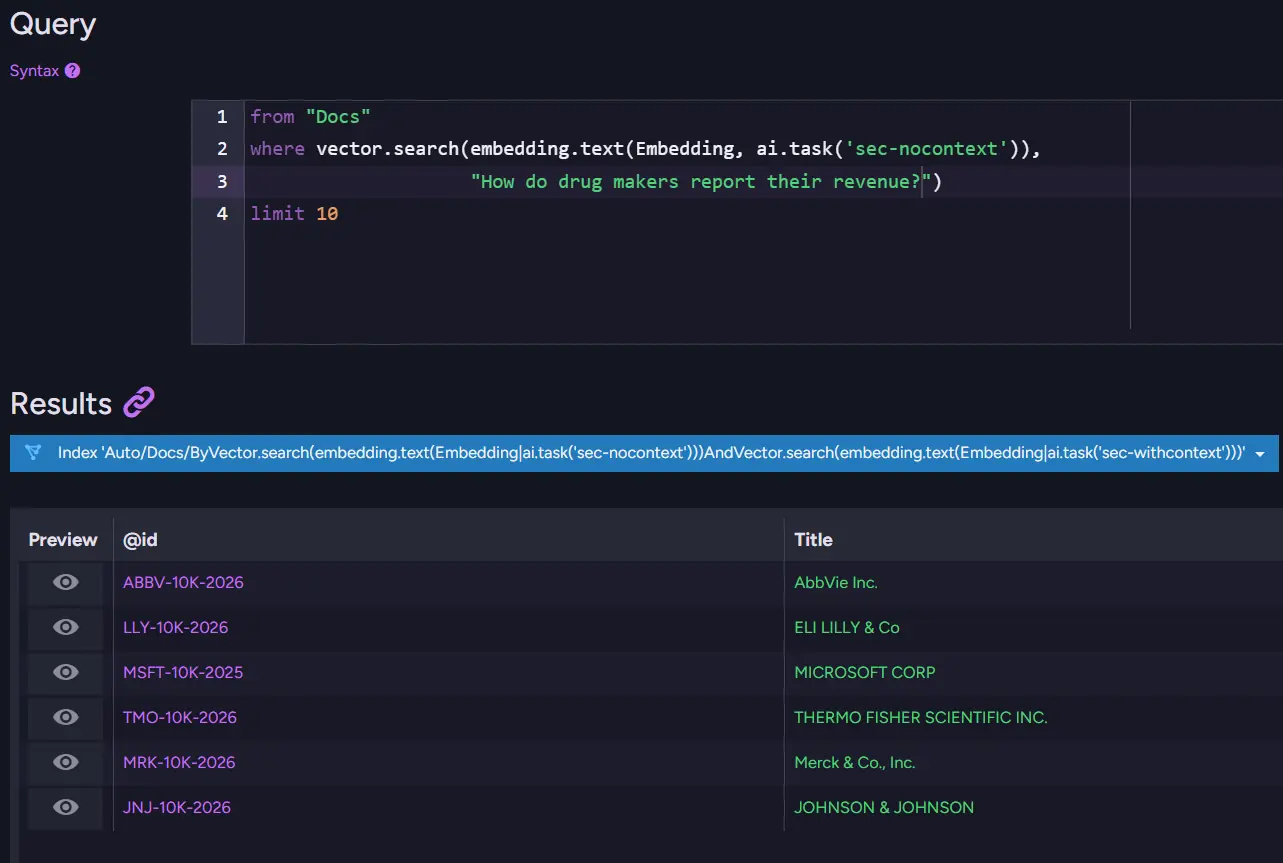
The query "How do drug makers report their revenue?" is a good example. Without the prefix, the search returned six pharmaceutical companies from corpus. With the prefix, the results were cleaner, but Johnson & Johnson fell out of the Top 10. That was the price for getting less irrelevant documents. The search became more focused, but also slightly less complete.
That trade-off shows up throughout the benchmark. The context prefix behaves a bit like a confidence amplifier. It pushes the search toward results it feels strongly about and away from weaker matches. For workloads where users want the single best document, that is a huge advantage. For workloads where users want every relevant document, even the borderline ones, there is a real cost.
The important thing is that F1 improved in both scenarios. The feature improved the overall F1 in both query sets. The difference is that company-specific searches got a free lunch, while category searches had to pay for some of that extra precision with a little recall.
When to use it?
Whether it's right for you depends on one question: do your users want the single best match, or every possible match?
The biggest wins showed up when important details were introduced in one part of a document and referenced much later. Maybe a report introduces a company near the beginning and then spends the next hundred pages discussing products, revenue, risks, and strategy without constantly repeating the company name. We can naturally keep that context in our heads. AI doesn't see the full context. Giving each chunk a small reminder of what document it belongs to can make a surprising difference.
The feature is particularly useful when users search for something specific. In our benchmark, queries that explicitly mentioned a company name saw improvements across every metric we measured. The context prefix helped the search return fewer irrelevant matches while making it even more likely that the correct document appeared near the top.
There are a few trade-offs to keep in mind. The first is that context is limited. Every token you spend on the prefix cannot be used for the chunk's original content. It also moves content into new embeddings, in process generating more chunks. That does not mean you should avoid longer prefixes, but it does mean you should be deliberate about what information you include. The goal is usually not to summarize the entire document. Instead, focus on the pieces of information that help explain the chunk itself. In our benchmark, a company name performed well because it provided context often missing from individual chunks.
Another trade-off is performance. Pulling a value from a document property is usually fast, but dynamically generating context when loading multiple related documents can significantly impact performance, since each operation adds processing for each embedded document.
Context Prefixes and Retrieval Behavior
We also noticed that adding context changes how vector search behaves.
In category-focused queries, the search became more confident and precise, but it also missed some relevant documents that had previously been returned.
If your users want the single best answer, that can be a worthwhile trade. If they need an exhaustive list of everything that might be relevant, you should test carefully before using the context prefix.
If you are unsure whether to use it, test it on a small piece of your own data. Create two embedding tasks, use the same chunking strategy for both, enable withContextPrefix(...) on one of them, and compare the results using the metrics that actually matter for your application. We wanted to know whether adding a small amount of document-level context would make a difference. The answer for us was yes, but the answer can change depending on your system.
Summary
withContextPrefix(...) injects document-level metadata into every embedding chunk, helping the model understand which document a fragment belongs to even when that information is absent from the chunk itself.
- The biggest wins come when key identifying information appears once at the start of a document and never repeats, such as a company name, report title, or category that individual chunks would otherwise lose entirely.
- The context prefix acts as a confidence amplifier: it narrows result sets and improves precision, but it can also drop borderline-relevant documents that would have otherwise ranked inside the top 10, so recall may fall for broad category queries.
- Token budget is a real constraint: every token given to the prefix is unavailable for chunk content, so keep prefixes short and focused on the single piece of missing context rather than trying to summarize the whole document.
- Before committing to the feature, run a controlled test on your own data: create two identical embedding tasks that differ only in the presence of
withContextPrefix(...), then compare precision, recall, and F1 for the query types your users actually issue.
Any questions about RavenDB features, or just want to hang out and talk with the RavenDB team? Join our Discord Community Server.