Connection String to OpenAI and OpenAI-Compatible Providers
-
This article explains how to define a connection string to the OpenAI Service,
enabling RavenDB to use OpenAI models for Embeddings generation tasks, Gen AI tasks, and AI agents. -
Use this connection string format to connect RavenDB to any OpenAI-compatible provider that offers a compatible API. As long as the provider follows the OpenAI API format, RavenDB will be able to use it for Embeddings generation, Gen AI tasks, and chat-based agent interactions.
-
In this article:
Define the connection string - from Studio
Configuring a text embedding model
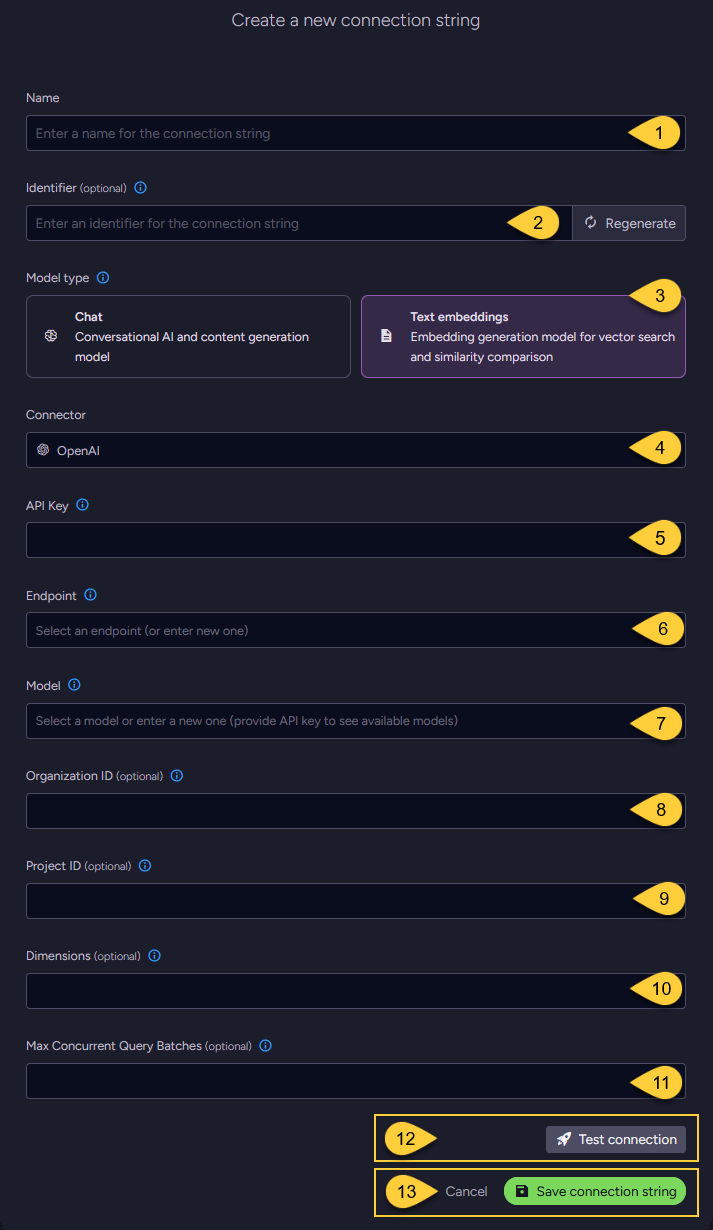
-
Name
Enter a name for this connection string. -
Identifier (optional)
Learn more about the identifier in the connection string identifier section. -
Model Type
Select "Text Embeddings". -
Connector
Select OpenAI from the dropdown menu. -
API key
Enter the API key used to authenticate requests to OpenAI or any OpenAI-compatible provider. -
Endpoint
Enter the base URL of the OpenAI API.
This can be the standard OpenAI endpoint or a URL provided by any OpenAI-compatible provider. -
Model
Select or enter the text embedding model to use, as provided by OpenAI or any OpenAI-compatible provider. -
Organization ID (optional)
- Set the organization ID to use for the
OpenAI-Organizationrequest header. - Users belonging to multiple organizations can set this value to specify which organization is used for an API request. Usage from these API requests will count against the specified organization's quota.
- If not specified, the header will be omitted, and the default organization will be billed.
You can change your default organization in your user settings. - Learn more in Setting up your organization
- Set the organization ID to use for the
-
Project ID (optional)
- Set the project ID to use for the
OpenAI-Projectrequest header. - Users who are accessing their projects through their legacy user API key can set this value to specify which project is used for an API request. Usage from these API requests will count as usage for the specified project.
- If not specified, the header will be omitted, and the default project will be accessed.
- Set the project ID to use for the
-
Dimensions (optional)
- Specify the number of dimensions for the output embeddings.
Supported only by text-embedding-3 and later models. - If not specified, the model's default dimensionality is used.
- Specify the number of dimensions for the output embeddings.
-
Max concurrent query batches: (optional)
- When making vector search queries, the content of the search terms must also be converted to embeddings to compare them against the stored vectors. Requests to generate such query embeddings via the AI provider are sent in batches.
- This parameter defines the maximum number of these batches that can be processed concurrently.
You can set a default value using the Ai.Embeddings.MaxConcurrentBatches configuration key.
-
Click Test Connection to confirm the connection string is set up correctly.
-
Click Save to store the connection string or Cancel to discard changes.
Configuring a chat model
-
When configuring a chat model, the UI displays the same base fields as those used for text embedding models,
including the connection string Name, optional Identifier, API Key, Endpoint, Model name, Organization ID, and Project ID. -
Additional settings specific to chat models are: Prompt Cache Key & Temperature.
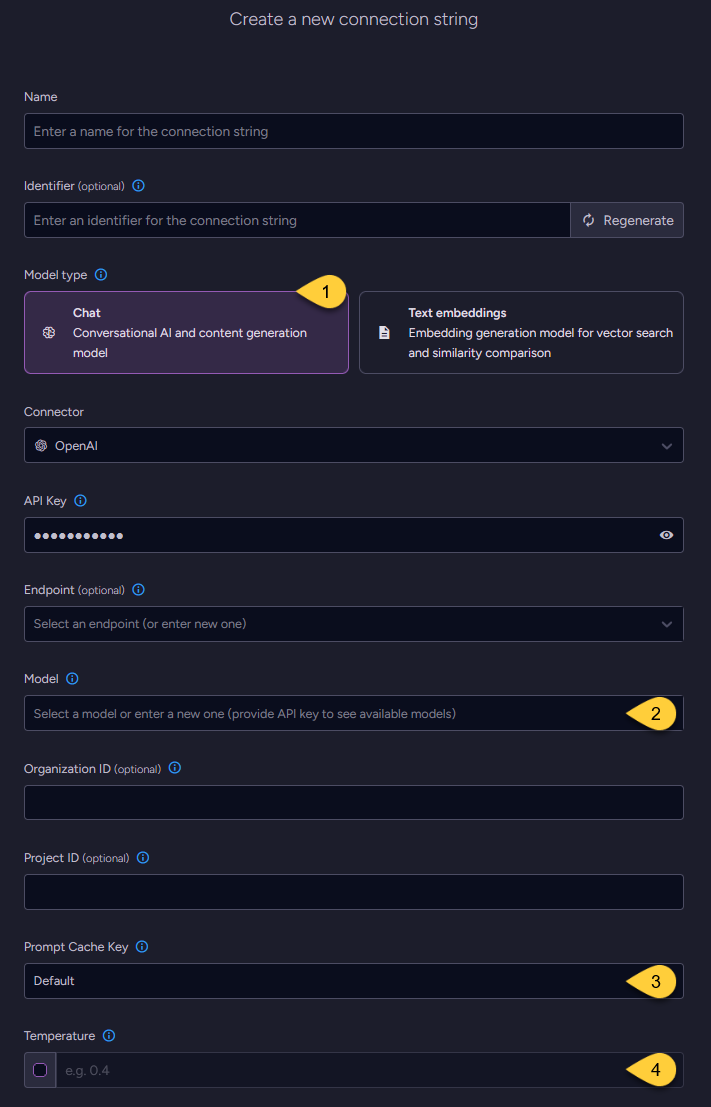
-
Model Type
Select "Chat". -
Model
Enter the name of the OpenAI model to use for chat completions. -
Prompt Cache Key (optional)
-
Controls whether RavenDB includes the
prompt_cache_keyfield in chat completion requests sent to the AI provider when using AI Agents. -
When enabled (set to True), RavenDB sends the Conversation's document ID in the
prompt_cache_keyfield with each request. This can help the AI provider identify requests that belong to the same conversation and reuse a previously cached prompt prefix (system prompt + prior messages). -
Why this helps:
AI providers typically process requests on many servers. Without a cache key, consecutive requests from the same conversation may be handled by different servers, each reprocessing the entire conversation from scratch. With the cache key, the provider can route the request to the same machine that handled the previous turn, where the computed prefix is likely still in memory. The provider then only needs to process the new messages, reducing latency and cost. -
The full conversation content is still sent with every request. The cache key is only a provider-side optimization hint. RavenDB does not control the provider's caching behavior.
-
Options:
Default-True(Enabled for OpenAI and OpenAI-compatible providers).True- Always send the cache key.False- Never send the cache key.
Set to False if your provider does not support the field and returns errors instead of ignoring it.
-
-
Temperature (optional)
The temperature setting controls the randomness and creativity of the model’s output.
Valid values typically range from0.0to2.0:- Higher values (e.g.,
1.0or above) produce more diverse and creative responses. - Lower values (e.g.,
0.2) result in more focused, consistent, and deterministic output. - If not explicitly set, OpenAI uses a default temperature of
1.0.
See OpenAI chat completions parameters.
- Higher values (e.g.,
Define the connection string - from the Client API
- Connection_string_for_text_embedding_model
- Connection_string_for_chat_model
using (var store = new DocumentStore())
{
// Define the connection string to OpenAI
var connectionString = new AiConnectionString
{
// Connection string Name & Identifier
Name = "ConnectionStringToOpenAI",
Identifier = "identifier-to-the-connection-string", // optional
// Model type
ModelType = AiModelType.TextEmbeddings,
// OpenAI connection settings
OpenAiSettings = new OpenAiSettings
{
ApiKey = "your-api-key",
Endpoint = "https://api.openai.com/v1",
// Name of text embedding model to use
Model = "text-embedding-3-small",
// Optionally, override the default maximum number of query embedding batches
// that can be processed concurrently
EmbeddingsMaxConcurrentBatches = 10
}
};
// Deploy the connection string to the server
var putConnectionStringOp =
new PutConnectionStringOperation<AiConnectionString>(connectionString);
var putConnectionStringResult = store.Maintenance.Send(putConnectionStringOp);
}
using (var store = new DocumentStore())
{
// Define the connection string to OpenAI
var connectionString = new AiConnectionString
{
// Connection string Name & Identifier
Name = "ConnectionStringToOpenAI",
Identifier = "identifier-to-the-connection-string", // optional
// Model type
ModelType = AiModelType.Chat,
// OpenAI connection settings
OpenAiSettings = new OpenAiSettings
{
ApiKey = "your-api-key",
Endpoint = "https://api.openai.com/v1",
// Name of chat model to use
Model = "gpt-4o",
// Optionally, set the model's temperature
Temperature = 0.4,
// Optionally, enable or disable prompt prefix caching
EnablePromptCache = true
}
};
// Deploy the connection string to the server
var putConnectionStringOp =
new PutConnectionStringOperation<AiConnectionString>(connectionString);
var putConnectionStringResult = store.Maintenance.Send(putConnectionStringOp);
}
Syntax
public class AiConnectionString
{
public string Name { get; set; }
public string Identifier { get; set; }
public AiModelType ModelType { get; set; }
public OpenAiSettings OpenAiSettings { get; set; }
}
public class OpenAiSettings : AbstractAiSettings
{
public string ApiKey { get; set; }
public string Endpoint { get; set; }
public string Model { get; set; }
public string OrganizationId { get; set; } // default organization is used if not set
public string ProjectId { get; set; } // default project is used if not set
// Relevant only for TEXT EMBEDDING models:
// Specifies the number of dimensions in the generated embedding vectors.
public int? Dimensions { get; set; } // optional
// Relevant only for CHAT models:
// Controls the randomness and creativity of the model’s output.
// Higher values (e.g., 1.0 or above) produce more diverse and creative responses.
// Lower values (e.g., 0.2) result in more focused and deterministic output.
// If set to 'null', the temperature is not sent and the model's default will be used.
public double? Temperature { get; set; } // optional
// Relevant only for CHAT models:
// Controls whether the 'prompt_cache_key' field is included in chat completion requests.
// When enabled, the conversation's document ID is sent as the cache key to the AI provider.
// Default: enabled (true) for OpenAI and OpenAI-compatible providers
public bool? EnablePromptCache { get; set; } // optional
}
public class AbstractAiSettings
{
public int? EmbeddingsMaxConcurrentBatches { get; set; }
}