Connection String to Ollama
-
This article explains how to define a connection string to Ollama,
enabling RavenDB to use Ollama models for Embeddings generation tasks, Gen AI tasks, and AI agents. -
In this article:
Define the connection string - from Studio
Configuring a text embedding model
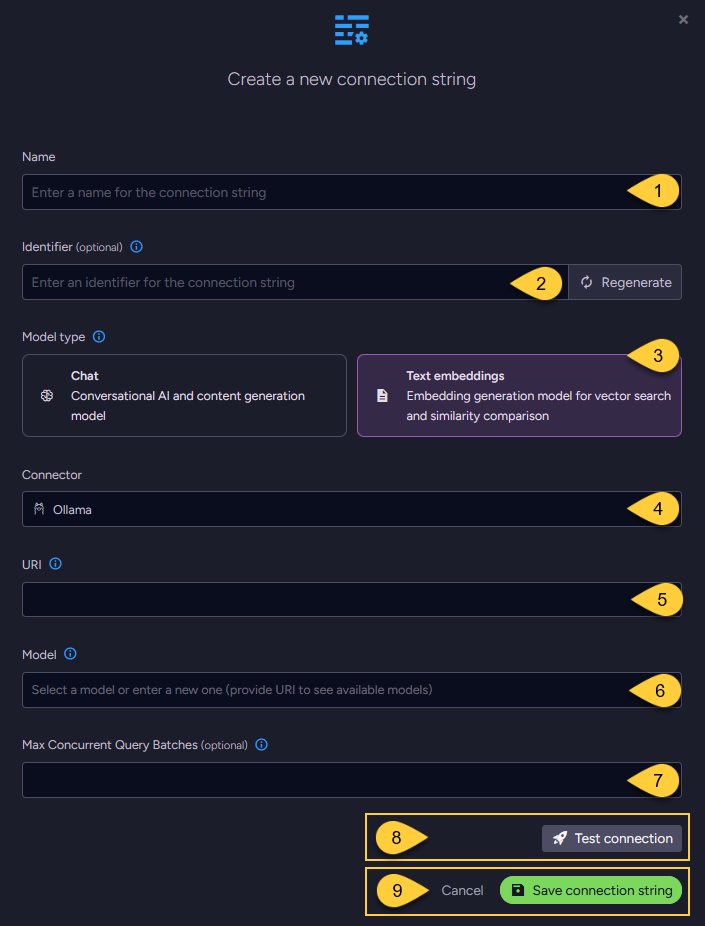
-
Name
Enter a name for this connection string. -
Identifier (optional)
Learn more about the identifier in the connection string identifier section. -
Model Type
Select "Text Embeddings". -
Connector
Select Ollama from the dropdown menu. -
URI
Enter the Ollama API URI. -
Model
Specify the Ollama text embedding model to use. -
Max concurrent query batches: (optional)
- When making vector search queries, the content of the search terms must also be converted to embeddings to compare them against the stored vectors.
Requests to generate such query embeddings via the AI provider are sent in batches. - This parameter defines the maximum number of these batches that can be processed concurrently.
You can set a default value using the Ai.Embeddings.MaxConcurrentBatches configuration key.
- When making vector search queries, the content of the search terms must also be converted to embeddings to compare them against the stored vectors.
-
Click Test Connection to confirm the connection string is set up correctly.
-
Click Save to store the connection string or Cancel to discard changes.
Configuring a chat model
-
When configuring a chat model, the UI displays the same base fields as those used for text embedding models,
including the connection string Name, optional Identifier, URI, and Model name. -
In addition, two fields are specific to chat models: Temperature and Thinking mode.
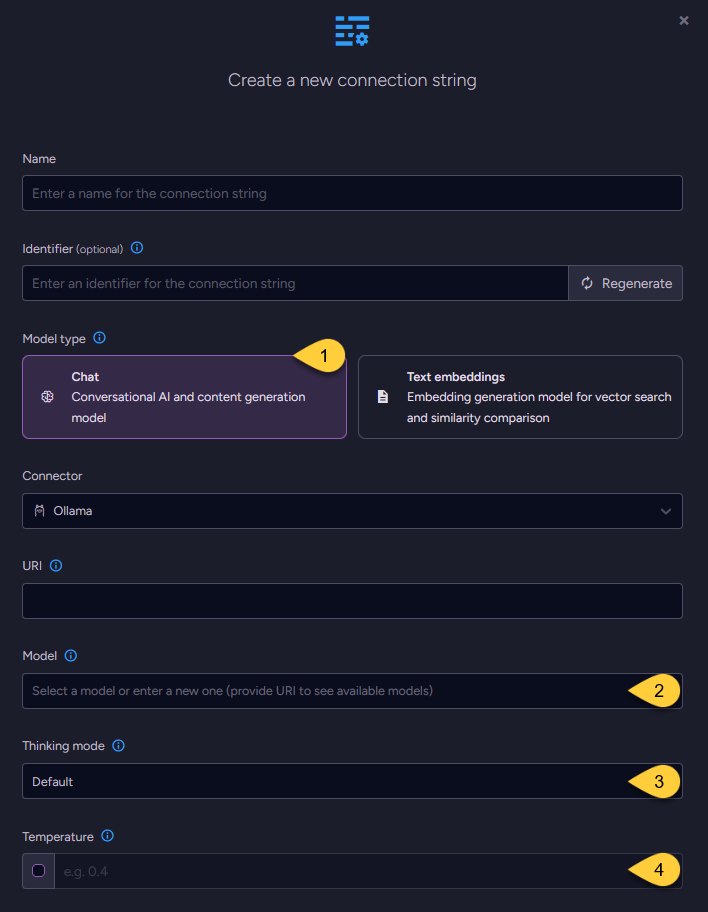
-
Model Type
Select "Chat". -
Model
Enter the name of the Ollama model to use for chat completions. -
Thinking mode (optional)
The thinking mode setting controls whether the model outputs its internal reasoning steps before returning the final answer.- When setting to
Enabled:
the model outputs a series of intermediate reasoning steps (chain of thought) before the final answer.
This may improve output quality for complex tasks, but increases response time and token usage. - When setting to
Disabled:
the model returns only the final answer, without exposing intermediate steps.
This is typically faster and more cost-effective (uses fewer tokens),
but may reduce quality on complex reasoning tasks. - When setting to
Default:
The model’s built-in default will be used. This value may vary depending on the selected model.
Set this parameter based on the trade-off between task complexity and speed/cost requirements.
- When setting to
-
Temperature (optional)
The temperature setting controls the randomness and creativity of the model’s output.
Valid values typically range from0.0to2.0:- Higher values (e.g.,
1.0or above) produce more diverse and creative responses. - Lower values (e.g.,
0.2) result in more focused, consistent, and deterministic output. - If not explicitly set, Ollama defaults to a temperature of
0.8.
See Ollama's parameters reference.
- Higher values (e.g.,
Define the connection string - from the Client API
- Connection_string_for_text_embedding_model
- Connection_string_for_chat_model
using (var store = new DocumentStore())
{
// Define the connection string to Ollama
var connectionString = new AiConnectionString
{
// Connection string Name & Identifier
Name = "ConnectionStringToOllama",
Identifier = "identifier-to-the-connection-string", // optional
// Model type
ModelType = AiModelType.TextEmbeddings,
// Ollama connection settings
OllamaSettings = new OllamaSettings
{
Uri = "http://localhost:11434",
// Name of text embedding model to use
Model = "mxbai-embed-large",
// Optionally, override the default maximum number of query embedding batches
// that can be processed concurrently
EmbeddingsMaxConcurrentBatches = 10
}
};
// Deploy the connection string to the server
var putConnectionStringOp =
new PutConnectionStringOperation<AiConnectionString>(connectionString);
var putConnectionStringResult = store.Maintenance.Send(putConnectionStringOp);
}
using (var store = new DocumentStore())
{
// Define the connection string to Ollama
var connectionString = new AiConnectionString
{
// Connection string Name & Identifier
Name = "ConnectionStringToOllama",
Identifier = "identifier-to-the-connection-string", // optional
// Model type
ModelType = AiModelType.Chat,
// Ollama connection settings
OllamaSettings = new OllamaSettings
{
Uri = "http://localhost:11434",
// Name of chat model to use
Model = "llama3:8b-instruct",
// Optionally, set the model's temperature
Temperature = 0.4,
// Optionally, set the model's thinking behavior
Think = true
}
};
// Deploy the connection string to the server
var putConnectionStringOp =
new PutConnectionStringOperation<AiConnectionString>(connectionString);
var putConnectionStringResult = store.Maintenance.Send(putConnectionStringOp);
}
Syntax
public class AiConnectionString
{
public string Name { get; set; }
public string Identifier { get; set; }
public AiModelType ModelType { get; set; }
public OllamaSettings OllamaSettings { get; set; }
}
public class OllamaSettings : AbstractAiSettings
{
// The base URI of your Ollama server
// For a local setup, use: "http://localhost:11434"
public string Uri { get; set; }
// The name of the model to use
public string Model { get; set; }
// Relevant only for CHAT models:
// Control whether the model outputs internal reasoning steps before returning the final answer.
// * 'true' - the model outputs intermediate reasoning steps (chain of thought)
// before the final answer.
// * 'false' - the model returns only the final answer,
// without exposing intermediate steps.
// * 'null' - the model’s default behavior is used.
public bool? Think { get; set; }
// Relevant only for chat models:
// Controls the randomness and creativity of the model’s output.
// Higher values (e.g., 1.0 or above) produce more diverse and creative responses.
// Lower values (e.g., 0.2) result in more focused and deterministic output.
// If set to 'null', the temperature is not sent and the model's default will be used.
public double? Temperature { get; set; }
}
public class AbstractAiSettings
{
public int? EmbeddingsMaxConcurrentBatches { get; set; }
}