AI agents: Overview
-
An AI agent is a highly customizable mediation component that an authorized client can tailor to its needs and install on the server. The agent serves the client by facilitating communication between the client, an LLM, and a RavenDB database.
-
Clients can use AI agents to automate complex workflows by leveraging LLM capabilities such as data analysis, decision-making, and natural language processing.
-
The LLM can use an AI agent to query the database and request the client to perform actions.
-
Granting an LLM access to a credible data source such as a company database can significantly enhance its ability to provide the client with accurate and context-aware responses. Such access can also mitigate LLM behaviors that harm its usability like 'hallucinations' and user-pleasing bias.
-
Delegating the communication with the LLM to an AI agent can significantly reduce client code complexity and development overhead.
-
In this article:
Defining and running an AI agent
AI agents can be created by RavenDB clients (providing they have database administration permissions).
They reside on a RavenDB server, and can be invoked by clients to, for example, handle user requests and respond to events tracked by the client.
An agent can serve multiple clients concurrently.
- The agent's layout, including its configuration, logic, and tools is shared by all the clients that use the agent.
- Conversations that clients conduct with the agent are isolated per conversation.
Each client maintains its own conversation instance with the agent with complete privacy, including -- Parameter values that the client may pass to the agent
- All conversation content and history
- Results received when the conversation ends
The main stages in defining an AI agent:
To define an AI agent, the client needs to specify -
-
A connection string to the AI model.
Create a connection string using the API
Create a connection string using Studio -
An agent configuration that defines the agent.
Define an agent configuration using the API
Define an agent configuration using StudioAn agent configuration includes -
-
Basic agent settings, like the unique ID by which the system recognizes the task.
-
A system prompt by which the agent instructs the AI model what its characteristics are, e.g. its role.
-
Optional agent parameters.
Agent parameters' values are provided by the client when it starts a conversation with the agent, and can be used in queries initiated by the LLM (see query tools below). -
Optional query tools.
The LLM will be able to invoke query tools freely to retrieve data from the database.- Read-only operations
Query tools can apply read operations only.
To make changes in the database, use action tools.Note that actions can be performed only by the client. The LLM can just request the client to perform actions on its behalf.
- Database access
The LLM has no direct access to the database. To use a query tool, it must send a query request to the agent, which will send the RQL query defined by the tool to the database and pass its results to the LLM. - Query parameters
The RQL query defined by a query tool may optionally include parameters, identified by a$prefix.
Both the user and the LLM can pass values to these parameters.
Users can pass values to query parameters through agent parameters, when the client starts a conversation with the agent.
The LLM can pass values to queries through a parameters schema, outlined as part of the query tool, when requesting the agent to run the query. - Initial-context queries
You can optionally set a query tool as an initial-context query.
Queries that are not set this way are invoked when the LLM requests the agent to run them.
Queries that are set as initial-context queries are executed by the agent immediately when it starts a conversation with the LLM, without waiting for the LLM to invoke them, to include data that is relevant for the conversation in the initial context sent to the LLM.
E.g., an initial-context query can provide the LLM, before the actual conversation starts, the last 5 orders placed by a customer, as context for an answer that the LLM is requested to provide about the customer's order history.
- Read-only operations
-
Optional action tools that the LLM will be able to invoke freely.
The LLM will be able to use these tools to request the client to perform actions.
-
What is a conversation:
A conversation is a communication session between the client, the agent, and the LLM that maintains the history of messages exchanged between these participants since the conversation began.
- The conversation starts when the client invokes the agent and provides it with an initial context.
- The conversation may include multiple "turns" of message exchanges between the client and the LLM, mediated by the agent.
- Each turn starts with a new user prompt from the client.
- During the turn, the LLM can trigger the agent to run queries or request the client to perform actions, using defined query and action tools.
- The turn ends with an LLM response to the user prompt.
The response may trigger a new turn (e.g., by requesting more information),
or be the final LLM response and end the conversation.
- The agent maintains the continuity of the conversation by storing all messages exchanged since the conversation began in a dedicated document in the
@conversationcollection and providing all stored messages to the LLM with each new agent message. - The conversation ends when the LLM provides the agent with its final response.
Initiate a conversation using the API
Initiate a conversation using Studio
Initiating a conversation:
To start a conversation with the LLM, the agent will send it an initial context that includes -
-
The pre-defined agent configuration (automatically sent by the agent) with:
- The system prompt
- A response object that defines the layout for the LLM response
- Optional agent parameters
- Optional Query tools
(and if any query tool is configured as an initial-context query - results for this query) - Optional Action tools
-
Values for agent parameters
If agent parameters were defined in the agent configuration, the client is required to provide their values to the agent when starting a conversation.E.g.,
The agent configuration may include an agent parameter calledemployeeId.
A query tool may include an RQL query likefrom Employees as E where id() == $employeeId, using this agent parameter.
When the client starts a conversation with the agent, it will be required to provide the value foremployeeId, e.g.employees/8-A.
When the LLM requests the agent to invoke this query tool, the agent will replace$employeeIdwithemployees/8-Abefore running the query.
See an example that utilizes this agent parameter.Providing query values when starting a conversation gives the client the ability to shape and limit the scope of LLM queries by its objectives.
-
Stored conversation messages
Since the LLM keeps no record of previous messages, the agent is responsible for allowing a continuous conversation.
It achieves this by automatically recording all messages of each conversation in a dedicated document in the@conversationscollection.
When the agent needs to continue a conversation, it will pull all previous messages from the@conversationscollection document, and send them to the LLM.
The conversation will remain available in the@conversationscollection even after it ends, so it can be resumed at any future time. -
A user prompt, set by the client, that defines, for example, a question or a request for particular information.
AI agent usage flowchart
The flowchart below illustrates interactions between the User, RavenDB client, AI agent, AI model, and RavenDB database.
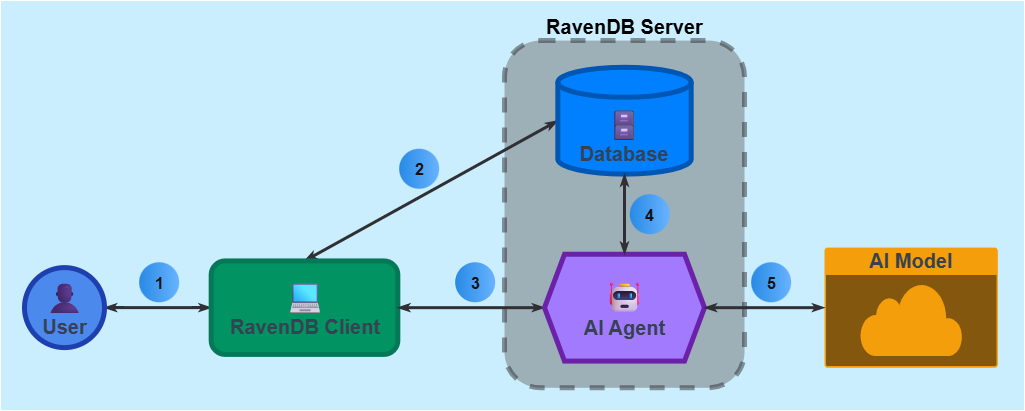
-
User
<->Client flow
Users can use clients that interact with the AI agent.
The user can provide agent parameters values through the client, and get responses from the agent. -
Client
<->Database flow
The client can interact with the database directly, either by its own initiative or as a result of AI agent action requests (query requests are handled by the agent). -
Client
<->Agent flow- To invoke an agent, the client needs to provide it with an initial context.
- During the conversation, the agent may send to the client action requests on behalf of the LLM.
- When the LLM provides the agent with its final response, the agent will provide it to the client.
The client does not need to reply to this message. - E.g., the client can pass the agent a research topic, a user prompt that guides the AI model to act as a research assistant, and all the messages that were included in the conversation so far.
The agent can respond with a summary of the research topic, and a request for the client to save it in the database.
-
Agent
<->Database flow- The agent can query the database on behalf of the AI model.
When the query ends, the agent will return its results to the AI model. - When the agent is requested to run a query that includes agent parameters, it will replace these parameters with values provided by the client before running the query.
- When the agent is requested to run a query that includes LLM parameters, it will replace these parameters with values provided by the LLM before running the query.
- The agent can query the database on behalf of the AI model.
-
Agent
<->Model flow- When a conversation is started, the agent needs to provide the AI model with an initial context, partly defined by the agent configuration and partly by the client.
- During the conversation, the AI model can respond to the agent with -
- Requests for queries.
If a query includes LLM parameters, the LLM will include values for them, and the agent will replace the parameters with these values, run the query, and return its results to the LLM.
If a query includes agent parameters, the agent will replace them with values provided by the client, run the query, and return its results to the LLM. - Requests for actions.
The agent will pass such requests to the client and return their results to the LLM. - The final response to the user prompt, in the layout defined by the response object.
The agent will pass the response to the client (which doesn't need to reply to it).
- Requests for queries.
Streaming LLM responses
Rather than wait for the LLM to finish generating a response and then pass it in its entirety to the client, the agent can stream response chunks (determined by the LLM, e.g. words or symbols) to the client one by one, immediately as each chunk is returned by the LLM, allowing the client to process and display the response gradually.
Streaming can ease the processing of lengthy LLM responses for clients, and create a better user experience by keeping users from waiting and providing them with a continuous, fluent interaction.
Streaming is supported by most AI models, including OpenAI services like GPT-4 and Ollama models.
Streaming LLM responses using the API
Reducing throughput and expediting LLM response
If throughput and LLM response time are considerations, the following suggestions can help optimize performance:
Define a chat trimming configuration:
The LLM doesn't keep conversation history. To allow a continuous conversation, the agent precedes each new message it sends to the LLM with all the messages that were exchanged in the conversation since it started.
To save traffic and tokens, you can summarize conversations using chat trimming. This can be helpful when transfer rate and cost are a concern or the context becomes too large to handle efficiently.
Configuring chat trimming using the API
Configuring chat trimming using Studio
Optimize query tools:
When creating query tools -
-
Provide the LLM with clear instructions on how to use each query tool effectively.
-
Narrow your queries:
- Design queries to return only the data that is relevant to the agent's role and the user's prompt.
- You can limit the scope of a query both in the RQL statement itself and by using agent parameters to filter results.
- Avoid overly broad queries that return large datasets, as they can overwhelm the LLM and lead to slower response times.
- Consider projecting only relevant properties and setting a limit on the number of results returned by each query to prevent excessive data transfer and processing, e.g. -
- no-limit
- set-limit
from Orders as O where O.ShipTo.Country == $countryfrom Orders as O where O.ShipTo.Country == $country select O.Employee, O.Lines.Quantity limit 4
-
Supervise querying:
- Test query tools with various prompts and scenarios to identify and address any performance bottlenecks.
- Monitor the performance of query tools in production to identify and address any issues that arise over time.
- Regularly review and update query tools to ensure they remain relevant and efficient as the database evolves.
Creating query tools using the API
Creating query tools using Studio
Set maximum number of querying iterations:
You can limit the number of times that the LLM is allowed to trigger database queries in response to a single user prompt.
Setting iterations limit using the API
Common use cases
AI agents are designed to easily integrate AI capabilities into applications and workflows. They can interact with users, intelligently retrieve and process data from proprietary databases, and apply actions based on roles they are requested to take and the data they have access to. Some of the tasks and applications they can be tailored to perform include -
Customer support chatbot agents
Agents can answer customer queries based on information stored in databases and internal knowledge bases, provide troubleshooting steps, and guide users through processes in real time.
Data analysis and reporting agents
Agents can analyze large datasets to extract relevant data and present it in a user-friendly format, escalate customer issues and application output, create reports and highlight points of interest, and help businesses make informed decisions.
Content generation agents
Agents can generate summaries, add automated comments to articles and application-generated content, reference readers to related material, and create marketing content based on user input and stored information.
Workflow automation agents
Agents can automate repetitive tasks like email sorting, spam filtering, form filling, or file organization.
Intelligent recommendation agents
Agents can provide personalized recommendations based on user preferences and available data, e.g. a library assistant suggesting books and other resources, an HR office assistant recommending rewards for employees based on their performance and available facilities near their residence, or an e-commerce assistant recommending products.