Archived Documents and Other Features
-
Once you have archived documents in your database (see how to enable and schedule document archiving),
RavenDB features can detect these documents and handle them in different ways. -
Some features, like indexes and data subscriptions, provide native support for configuring whether to:
- Exclude archived documents from processing, reducing index size and improving query relevance.
- Include only archived documents, for tasks that target archived data specifically.
- Process both archived and non-archived documents when needed.
-
Other features can manage archived documents differently based on their purpose. For example:
- ETL tasks can skip or selectively process archived documents.
- Archived documents can be included or excluded when exporting or importing data.
-
Limiting processing to either archived or non-archived documents may improve performance by reducing workload and transfer volume.
-
Learn more below about how various RavenDB features interact with archived documents.
-
In this article:
- Archived documents and indexing
- Archived documents and querying
- Archived documents and data subscriptions
- Archived documents and document extensions
- Archived documents and smuggler (export/import)
- Archived documents and expiration
- Archived documents and ETL
- Archived documents and backup
- Archived documents and replication
- Archived documents and patching
Archived documents and indexing
-
Indexing performance may decline as the database grows, since a larger number of documents increases indexing load, expands index size, and can eventually reduce query speed.
-
Archiving documents and excluding them from indexing can be an effective way to maintain performance.
By removing low-priority or infrequently accessed documents from the indexing process, RavenDB can create smaller, faster indexes focused on current or high-value data. This also improves the relevance and responsiveness of queries, as they execute over a smaller and more meaningful dataset. -
Configuring indexing behavior - Static indexes:
- At the database level or server-wide:
To control whether static indexes process archived documents from the source collection,
set the Indexing.Static.ArchivedDataProcessingBehavior configuration key at either the database level or server-wide (default:ExcludeArchived). - Note that this setting applies only to static-indexes that are using Documents as their data source.
This global configuration does Not apply to static-indexes based on Time Series or Counters, which default to
IncludeArchived. - Per index:
You can override this global behavior per-index directly in the index definition, using the Client API from the Studio
(see the examples below).
- At the database level or server-wide:
-
Configuring indexing behavior - Auto indexes:
- At the database level or server-wide:
To control whether auto-indexes process archived documents at the database level or server-wide,
set the Indexing.Auto.ArchivedDataProcessingBehavior configuration key (defaultExcludeArchived). - Per index:
Unlike static indexes, you cannot configure this behavior per auto-index,
because dynamic queries (which trigger auto-index creation) do not provide a way to control this setting.
- At the database level or server-wide:
-
The available configuration options are:
ExcludeArchived: only non-archived documents are processed by the index.IncludeArchived: both archived and non-archived documents are processed by the index.ArchivedOnly: only archived documents are processed by the index.
Configuring archived document processing for a static index - from the Client API
You can configure how a static index handles archived documents when creating the index using the Client API. This setting will override the global configuration defined by the Indexing.Static.ArchivedDataProcessingBehavior configuration key.
Example:
- LINQ_index
- JS_index
- IndexDefinitionBuilder
public class Orders_ByOrderDate :
AbstractIndexCreationTask<Order, Orders_ByOrderDate.IndexEntry>
{
public class IndexEntry
{
public DateTime OrderDate { get; set; }
}
public Orders_ByOrderDate()
{
Map = orders => from order in orders
select new IndexEntry
{
OrderDate = order.OrderedAt
};
// Configure whether the index should process data from archived documents:
// ========================================================================
ArchivedDataProcessingBehavior =
// You can set to 'ExcludeArchived', 'IncludeArchived, or 'ArchivedOnly'
Raven.Client.Documents.DataArchival.ArchivedDataProcessingBehavior.IncludeArchived;
}
}
public class Orders_ByOrderDate_JS : AbstractJavaScriptIndexCreationTask
{
public Orders_ByOrderDate_JS()
{
Maps = new HashSet<string>()
{
@"map('Orders', function (order) {
return {
OrderDate: order.OrderedAt
};
})"
};
// Configure whether the index should process data from archived documents:
// ========================================================================
ArchivedDataProcessingBehavior =
// Can set the to 'ExcludeArchived', 'IncludeArchived, or 'ArchivedOnly'
Raven.Client.Documents.DataArchival.ArchivedDataProcessingBehavior.IncludeArchived;
}
}
var indexDefinition = new IndexDefinitionBuilder<Order>()
{
Map = orders => from order in orders
select new { order.OrderedAt }
}
.ToIndexDefinition(new DocumentConventions());
indexDefinition.Name = "Orders/ByOrderDate";
// Configure whether the index should process data from archived documents:
// ========================================================================
indexDefinition.ArchivedDataProcessingBehavior =
// You can set to 'ExcludeArchived', 'IncludeArchived, or 'ArchivedOnly'
ArchivedDataProcessingBehavior.IncludeArchived;
store.Maintenance.Send(new PutIndexesOperation(indexDefinition));
When a static-index is configured to include both archived and non-archived documents in its processing,
you can also apply custom logic based on the presence of the @archived metadata property.
For example:
- LINQ_index
- JS_index
- IndexDefinition
public class Orders_ByArchivedStatus :
AbstractIndexCreationTask<Order, Orders_ByArchivedStatus.IndexEntry>
{
public class IndexEntry
{
public bool? isArchived { get; set; }
public DateTime? OrderDate { get; set; }
public string ShipToCountry { get; set; }
}
public Orders_ByArchivedStatus()
{
Map = orders => from order in orders
let metadata = MetadataFor(order)
// Retrieve the '@archived' metadata property from the document:
let archivedProperty =
metadata.Value<bool?>(Raven.Client.Constants.Documents.Metadata.Archived)
// Alternative syntax:
// let archivedProperty =
// (bool?)metadata[Raven.Client.Constants.Documents.Metadata.Archived]
select new IndexEntry
{
// Index whether the document is archived:
isArchived = archivedProperty == true,
// Index the order date only if the document is archived:
OrderDate = archivedProperty == true ? order.OrderedAt : null,
// Index the destination country only if the document is not archived:
ShipToCountry = archivedProperty == null ? order.ShipTo.Country : null
};
ArchivedDataProcessingBehavior =
Raven.Client.Documents.DataArchival.ArchivedDataProcessingBehavior.IncludeArchived;
}
}
public class Orders_ByArchivedStatus_JS : AbstractJavaScriptIndexCreationTask
{
public Orders_ByArchivedStatus_JS()
{
Maps = new HashSet<string>()
{
@"map('Orders', function (order) {
var metadata = metadataFor(order);
var archivedProperty = metadata['@archived'];
var isArchived = (archivedProperty === true);
var orderDate = isArchived ? order.OrderedAt : null;
var shipToCountry = !isArchived ? order.ShipTo.Country : null;
return {
IsArchived: isArchived,
OrderDate: orderDate,
ShipToCountry: shipToCountry
};
})"
};
ArchivedDataProcessingBehavior =
Raven.Client.Documents.DataArchival.ArchivedDataProcessingBehavior.IncludeArchived;
}
}
var indexDefinition = new IndexDefinition
{
Name = "Orders/ByArchivedStatus",
Maps = new HashSet<string>
{
@"from order in docs.Orders
let metadata = MetadataFor(order)
let archivedProperty = (bool?)metadata[""@archived""]
select new
{
IsArchived = archivedProperty == true,
OrderDate = archivedProperty == true ? order.OrderedAt : null,
ShipToCountry = archivedProperty == null ? order.ShipTo.Country : null
}"
},
ArchivedDataProcessingBehavior = ArchivedDataProcessingBehavior.IncludeArchived
};
store.Maintenance.Send(new PutIndexesOperation(indexDefinition));
Configuring archived document processing for a static index - from the Studio
You can configure how a static index handles archived documents directly from the Studio.
This setting will override the global configuration defined by the Indexing.Static.ArchivedDataProcessingBehavior configuration key.
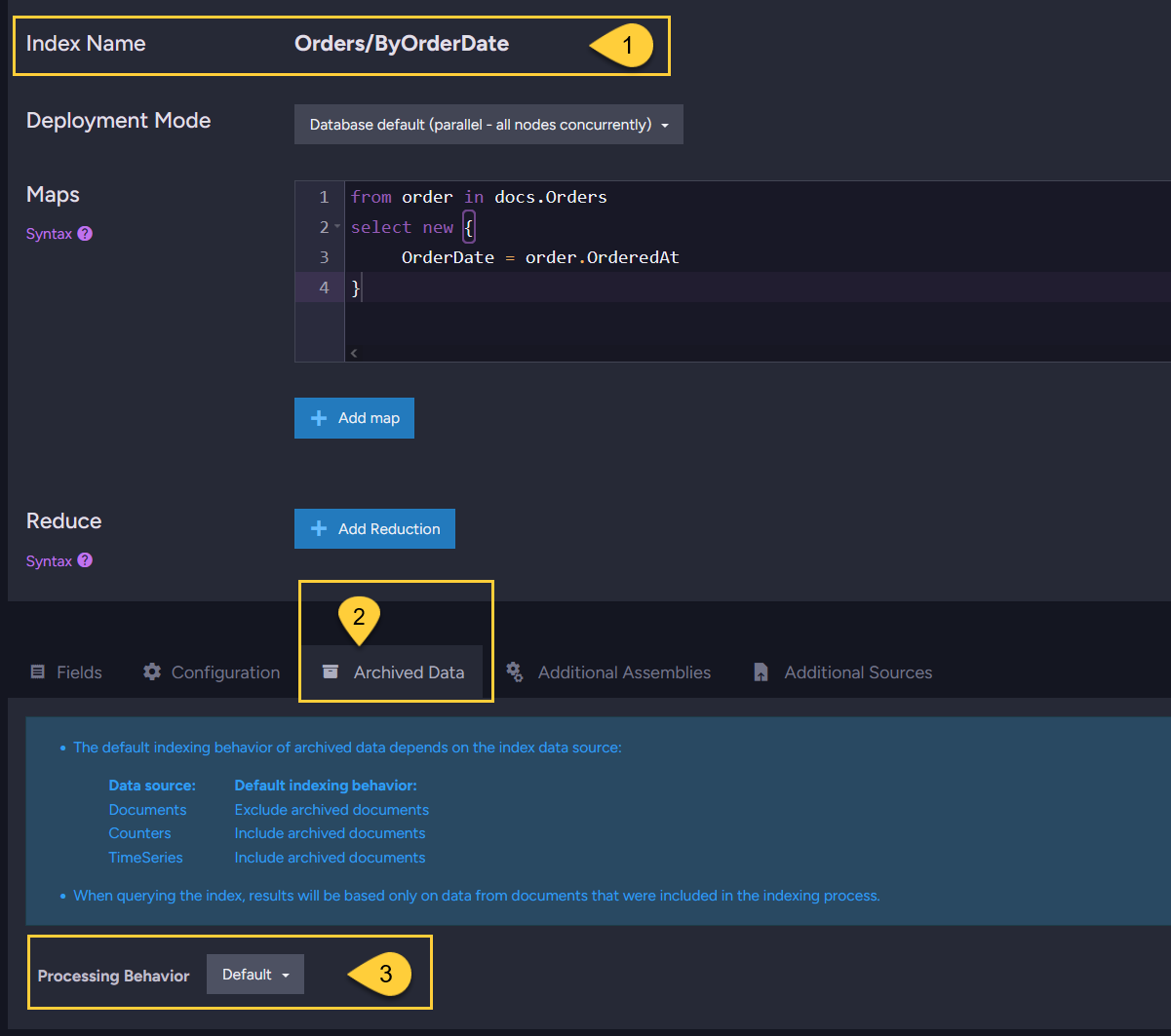
- Open the Indexes list view and select the index you want to configure, or create a new index.
- Scroll down and open the Archived Data tab.
- Click to select how this index should process archived documents:
- Default: The index will use the behavior set by the global configuration.
- Exclude Archived: Index only non-archived documents.
- Include Archived: Index both archived and non-archived documents.
- Archived Only: Index only archived documents.

Archived documents and querying
-
Full collection queries:
- Queries that scan an entire collection without any filtering condition (e.g.
from Orders) will include archived documents. - These queries are not influenced by indexing configuration related to archived documents because they do not use indexes.
- Learn more about full collection queries in Full collection query.
- Queries that scan an entire collection without any filtering condition (e.g.
-
Dynamic queries (auto-indexes):
- When making a dynamic query, RavenDB creates an auto-index to serve it. Whether that index processes archived documents depends on the value of the Indexing.Auto.ArchivedDataProcessingBehavior configuration key at the time the query is made.
- Once created, the auto-index retains that behavior. Query results will continue to reflect the configuration that was in effect when the index was first built - even if the setting is changed later.
- Learn more about dynamic queries in Query a collection - with filtering.
-
Querying static-indexes:
- When querying a static-index, the results will include, exclude, or consist solely of archived documents depending on how the static-index was configured.
The index behavior is determined by:
- the value of the Indexing.Static.ArchivedDataProcessingBehavior configuration key at the time the static-index was created, or -
- the explicit setting in the index definition, which overrides the global configuration key.
- The index's archived data processing behavior can be modified after its creation using the Studio or the Client API.
- When querying a static-index, the results will include, exclude, or consist solely of archived documents depending on how the static-index was configured.
The index behavior is determined by:
Archived documents and subscriptions
- Processing large volumes of documents in data subscriptions increases the workload on both the server and subscription workers.
- You can reduce this load by defining the subscription query to exclude archived documents, include only archived documents, or process both archived and non-archived data.
This gives you control over which documents are sent to workers - helping you focus on the most relevant data and reduce unnecessary processing. - Configuring the subscription task behavior:
- At the database level or server-wide:
To control whether queries in data subscription tasks process archived documents,
set theSubscriptions.ArchivedDataProcessingBehaviorconfiguration key at either the database level or server-wide
(default:ExcludeArchived). - Per task:
You can override this global behavior per data subscription task directly in the task definition,
using the Client API or from the Studio (see the examples below).
- At the database level or server-wide:
- The available configuration options are:
ExcludeArchived: only non-archived documents are processed by the subscription query.IncludeArchived: both archived and non-archived documents are processed by the subscription query.ArchivedOnly: only archived documents are processed by the subscription query.
Configuring archived document processing for a data subscription task - from the Client API
You can configure how a subscription task handles archived documents when creating the subscription using the Client API.
This setting will override the global configuration defined by the Subscriptions.ArchivedDataProcessingBehavior configuration key.
Example:
- Generic-syntax
- RQL-syntax
var subscriptionName = store.Subscriptions
.Create<Order>(new SubscriptionCreationOptions<Order>()
{
Name = "ArchivedOrdersSubscription",
// Workers that will subscribe to this subscription task
// will receive only archived documents from the 'Orders' collection.
ArchivedDataProcessingBehavior = ArchivedDataProcessingBehavior.ArchivedOnly
// You can set the behavior to 'ExcludeArchived', 'IncludeArchived, or 'ArchivedOnly'
});
var subscriptionName = store.Subscriptions
.Create(new SubscriptionCreationOptions()
{
Name = "ArchivedOrdersSubscription",
Query = "from Orders",
// Workers that will subscribe to this subscription task
// will receive only archived documents from the 'Orders' collection.
ArchivedDataProcessingBehavior = ArchivedDataProcessingBehavior.ArchivedOnly
// You can set the behavior to 'ExcludeArchived', 'IncludeArchived, or 'ArchivedOnly'
});
Configuring archived document processing for a data subscription task - from the Studio
You can configure how a subscription task handles archived documents directly from the Studio.
This setting will override the global configuration defined by the Subscriptions.ArchivedDataProcessingBehavior configuration key.
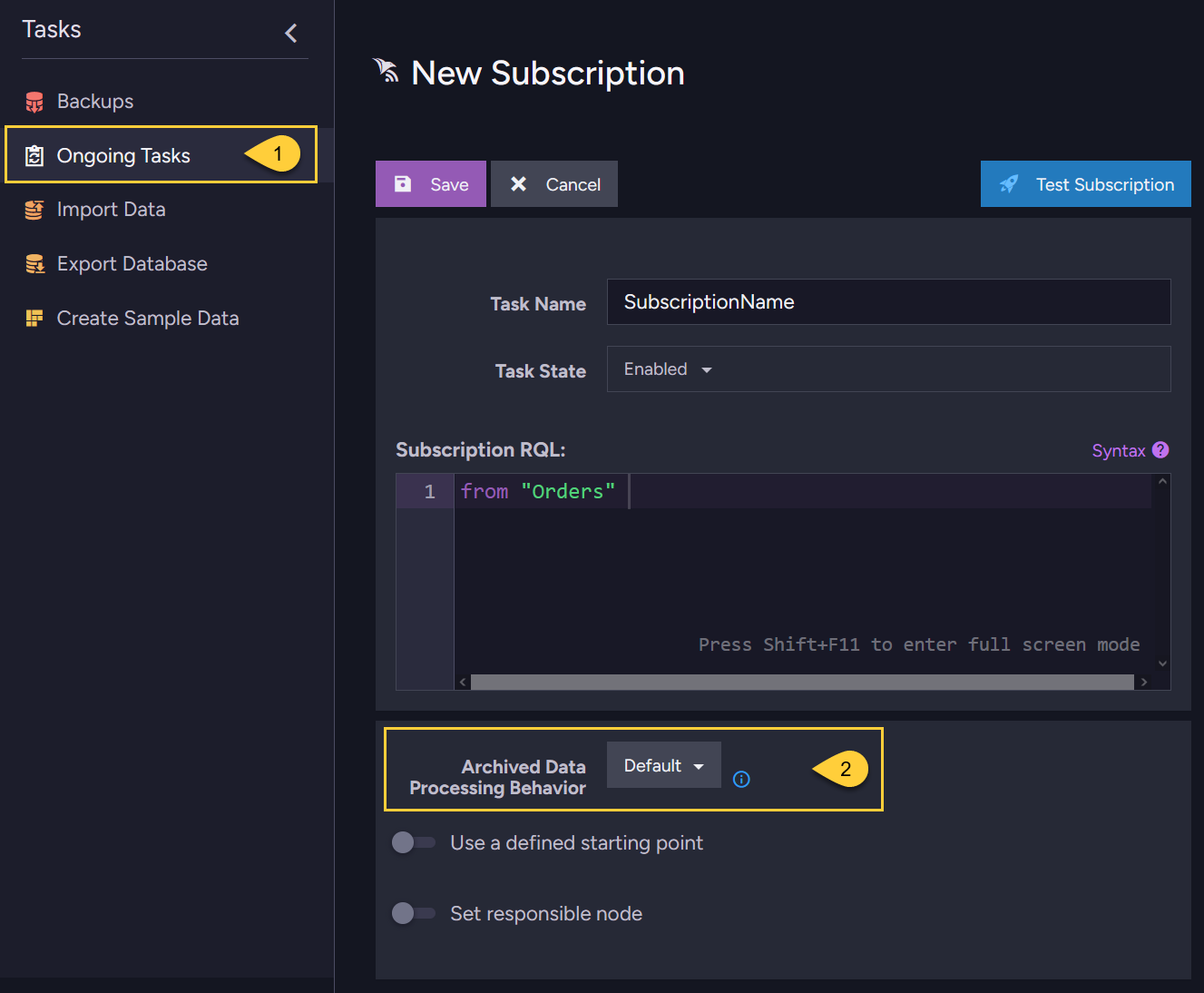
- Open the Ongoing tasks list view and select the subscription task you want to configure,
or create a new subscription. - Click to select how the subscription query should process archived documents:
- Default: The subscription will use the behavior set by the global configuration.
- Exclude Archived: Process only non-archived documents.
- Include Archived: Process both archived and non-archived documents.
- Archived Only: Process only archived documents.
Archived documents and document extensions
-
Attachments:
- Attachments are Not archived (compressed), even if the document they belong to is archived.
-
Counters:
- Counters are Not archived (compressed), even if the document they belong to is archived.
- Unlike indexes whose source data is Documents - which default to
ExcludeArchived-
indexes whose source data is Counters do process archived documents by default (IncludeArchived).
This behavior can be modified in the index definition.
-
Time series:
- Time series are Not archived (compressed), even if the document they belong to is archived.
- Unlike indexes whose source data is Documents - which default to
ExcludeArchived-
indexes whose source data is Time series do process archived documents by default (IncludeArchived).
This behavior can be modified in the index definition.
-
Revisions:
- No revision is created at the time the server archives a document, even if the Revisions feature is enabled.
- However, if you modify an archived document (when Revisions are enabled), a revision is created for that document - and that revision is archived as well.
Archived documents and smuggler (export/import)
You can control whether archived documents are included when exporting or importing a database.
Export/Import archived documents - from the Client API
Smuggler, RavenDB’s tool for database export and import, can be configured to include or exclude archived documents. By default, archived documents are included in the operation.
In this example, exported data excludes archived documents:
var exportOperation = store.Smuggler.ExportAsync(
new DatabaseSmugglerExportOptions()
{
// Export only non-archived documents:
IncludeArchived = false
}, "DestinationFilePath");
In this example, imported data includes archived documents:
var importOperation = store.Smuggler.ImportAsync(
new DatabaseSmugglerImportOptions()
{
// Include archived documents in the import:
IncludeArchived = true
}, "SourceFilePath");
Export archived documents - from the Studio
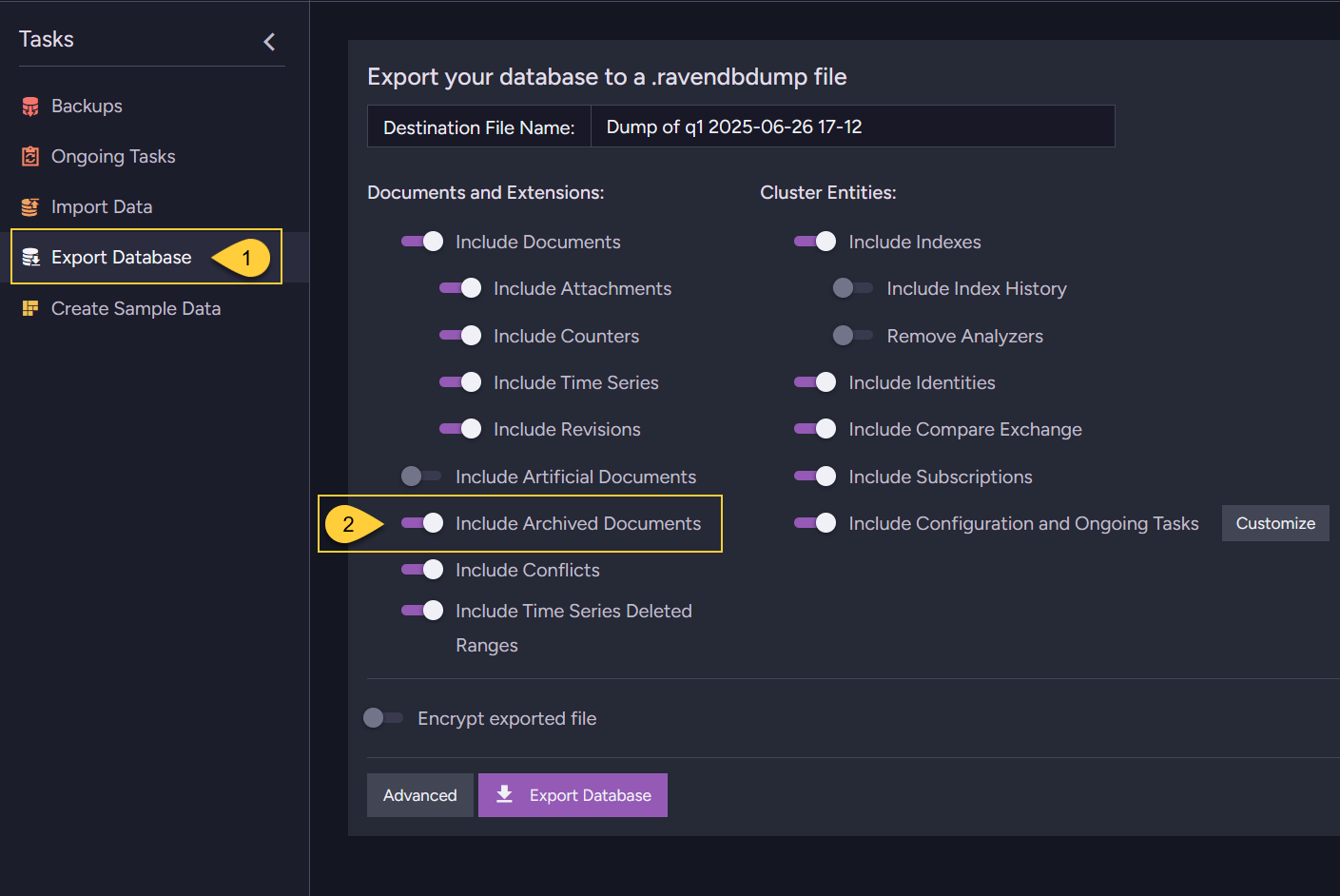
- Go to Tasks > Export Database.
- Toggle the Include archived documents option to control whether archived documents are included in the database export.
Import archived documents - from the Studio
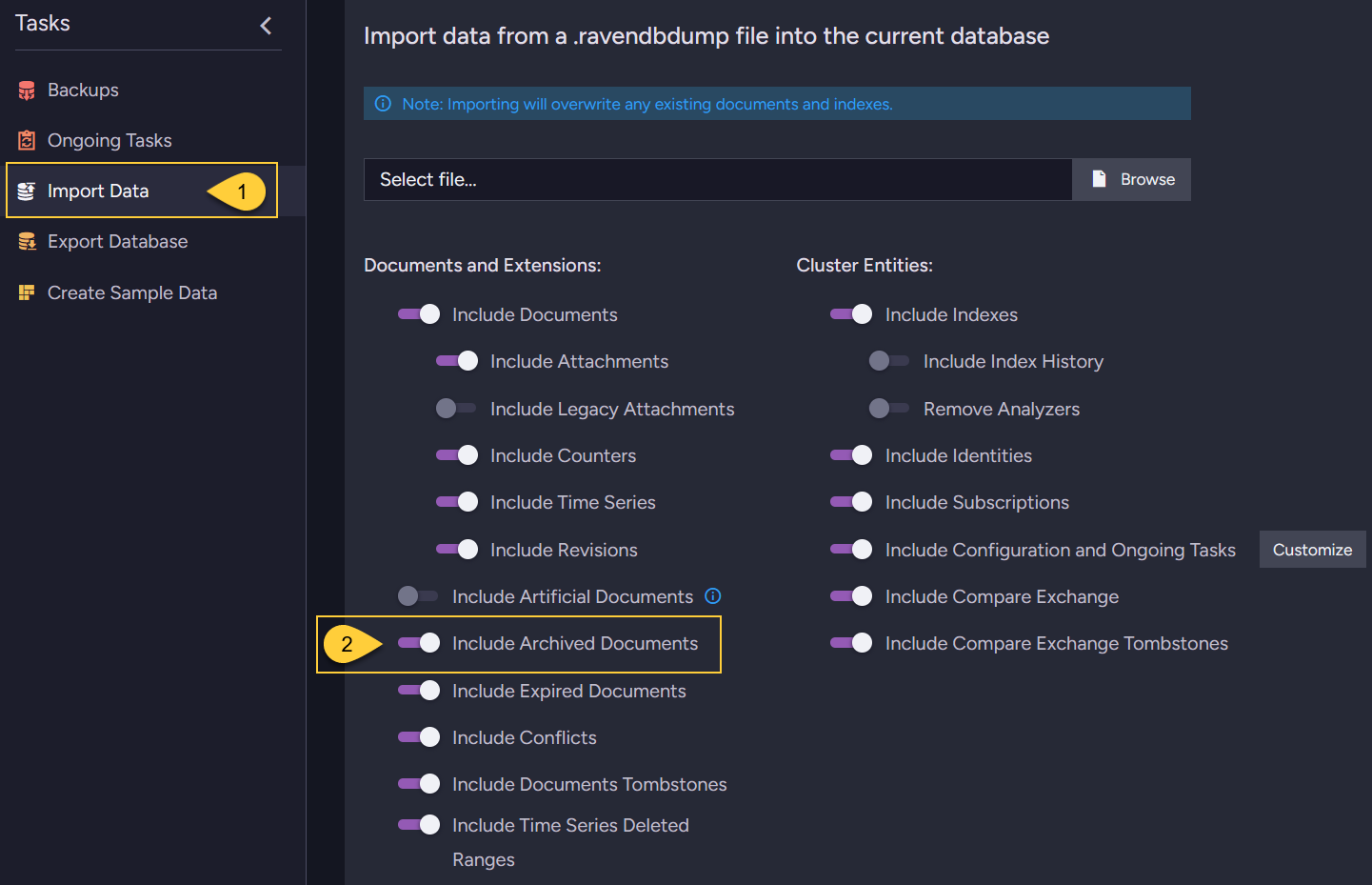
- Go to Tasks > Import Data.
- Toggle the Include archived documents option to control whether archived documents are included in the import.
Archived documents and expiration
-
Archiving can be used alongside other features, such as Document expiration.
-
For example, a document can be scheduled to be archived after six months and expired after one year.
This allows you to keep recent documents active and quickly accessible, move older documents to archival storage where slower access is acceptable, and eventually remove documents that are no longer needed. -
In the following example, both the
@archive-atand the@expiresmetadata properties have been added to documentcompanies/90-Ato schedule it for archiving and expiration, respectively:
{
"Name": "Wilman Kala",
"Phone": "90-224 8858",
...
"@metadata": {
"@archive-at": "2026-01-06T22:45:30.018Z",
"@expires": "2026-07-06T22:45:30.018Z",
"@collection": "Companies",
...
}
}
Archived documents and ETL
-
An ETL transformation script can examine each source document’s metadata for the existence of the
@archived: trueproperty, which indicates that the document is archived. Based on this check, the script can decide how to handle the document - for example, skip it entirely or send only selected fields. -
With RavenDB ETL, documents that are archived in the source database and sent to the target are not archived in the destination database.
-
In the following example, the ETL script checks whether the document is archived, and skips it if it is:
var isArchived = this['@metadata']['@archived'];
if (isArchived === true) {
return; // Do not process archived documents
}
// Transfer only non-archived documents to the target
loadToOrders(this);
Archived documents and backup
-
Archived documents are included in database backups (both logical backups and snapshots),
no special configuration is required. -
When restoring a database from a backup, archived documents are restored as well,
and their archived status is preserved.
Archived documents and replication
Archived documents are included in Internal replication,
External replication, and Hub/Sink replication -
no special configuration is required.
Archived documents and patching
-
Patching can be used to schedule multiple documents for archiving. See the dedicated sections:
Schedule multiple documents for archiving - from the Studio.
Schedule multiple documents for archiving - from the Client API. -
Patching is used to unarchive documents.
See the dedicated article Unarchiving documents. -
When cloning an archived document using the
putmethod within a patching script
(see this clone document example) the cloned document will Not be archived,
and the@archived: trueproperty will be removed from the cloned document.