Indexing Nested data
-
JSON documents can have nested structures, where one document contains other objects or arrays of objects.
-
Use a static-index to facilitate querying for documents based on the nested data.
-
In this page:
Sample data
- The examples in this article are based on the following Classes and Sample Data:
- Class
- Sample_data
public class OnlineShop
{
public string ShopName { get; set; }
public string Email { get; set; }
public List<TShirt> TShirts { get; set; } // Nested data
}
public class TShirt
{
public string Color { get; set; }
public string Size { get; set; }
public string Logo { get; set; }
public decimal Price { get; set; }
public int Sold { get; set; }
}
// Creating sample data for the examples in this article:
// ======================================================
var onlineShops = new[]
{
// Shop1
new OnlineShop { ShopName = "Shop1", Email = "sales@shop1.com", TShirts = new List<TShirt> {
new TShirt { Color = "Red", Size = "S", Logo = "Bytes and Beyond", Price = 25, Sold = 2 },
new TShirt { Color = "Red", Size = "M", Logo = "Bytes and Beyond", Price = 25, Sold = 4 },
new TShirt { Color = "Blue", Size = "M", Logo = "Query Everything", Price = 28, Sold = 5 },
new TShirt { Color = "Green", Size = "L", Logo = "Data Driver", Price = 30, Sold = 3}
}},
// Shop2
new OnlineShop { ShopName = "Shop2", Email = "sales@shop2.com", TShirts = new List<TShirt> {
new TShirt { Color = "Blue", Size = "S", Logo = "Coffee, Code, Repeat", Price = 22, Sold = 12 },
new TShirt { Color = "Blue", Size = "M", Logo = "Coffee, Code, Repeat", Price = 22, Sold = 7 },
new TShirt { Color = "Green", Size = "M", Logo = "Big Data Dreamer", Price = 25, Sold = 9 },
new TShirt { Color = "Black", Size = "L", Logo = "Data Mining Expert", Price = 20, Sold = 11 }
}},
// Shop3
new OnlineShop { ShopName = "Shop3", Email = "sales@shop3.com", TShirts = new List<TShirt> {
new TShirt { Color = "Red", Size = "S", Logo = "Bytes of Wisdom", Price = 18, Sold = 2 },
new TShirt { Color = "Blue", Size = "M", Logo = "Data Geek", Price = 20, Sold = 6 },
new TShirt { Color = "Black", Size = "L", Logo = "Data Revolution", Price = 15, Sold = 8 },
new TShirt { Color = "Black", Size = "XL", Logo = "Data Revolution", Price = 15, Sold = 10 }
}}
};
using (var session = store.OpenSession())
{
foreach (var shop in onlineShops)
{
session.Store(shop);
}
session.SaveChanges();
}
Simple index - Single index-entry per document
public class Shops_ByTShirt_Simple : AbstractIndexCreationTask<OnlineShop>
{
public class IndexEntry
{
// The index-fields:
public IEnumerable<string> Colors { get; set; }
public IEnumerable<string> Sizes { get; set; }
public IEnumerable<string> Logos { get; set; }
}
public Shops_ByTShirt_Simple()
{
Map = shops => from shop in shops
// Creating a SINGLE index-entry per document:
select new IndexEntry
{
// Each index-field will hold a collection of nested values from the document
Colors = shop.TShirts.Select(x => x.Color),
Sizes = shop.TShirts.Select(x => x.Size),
Logos = shop.TShirts.Select(x => x.Logo)
};
}
}
-
-
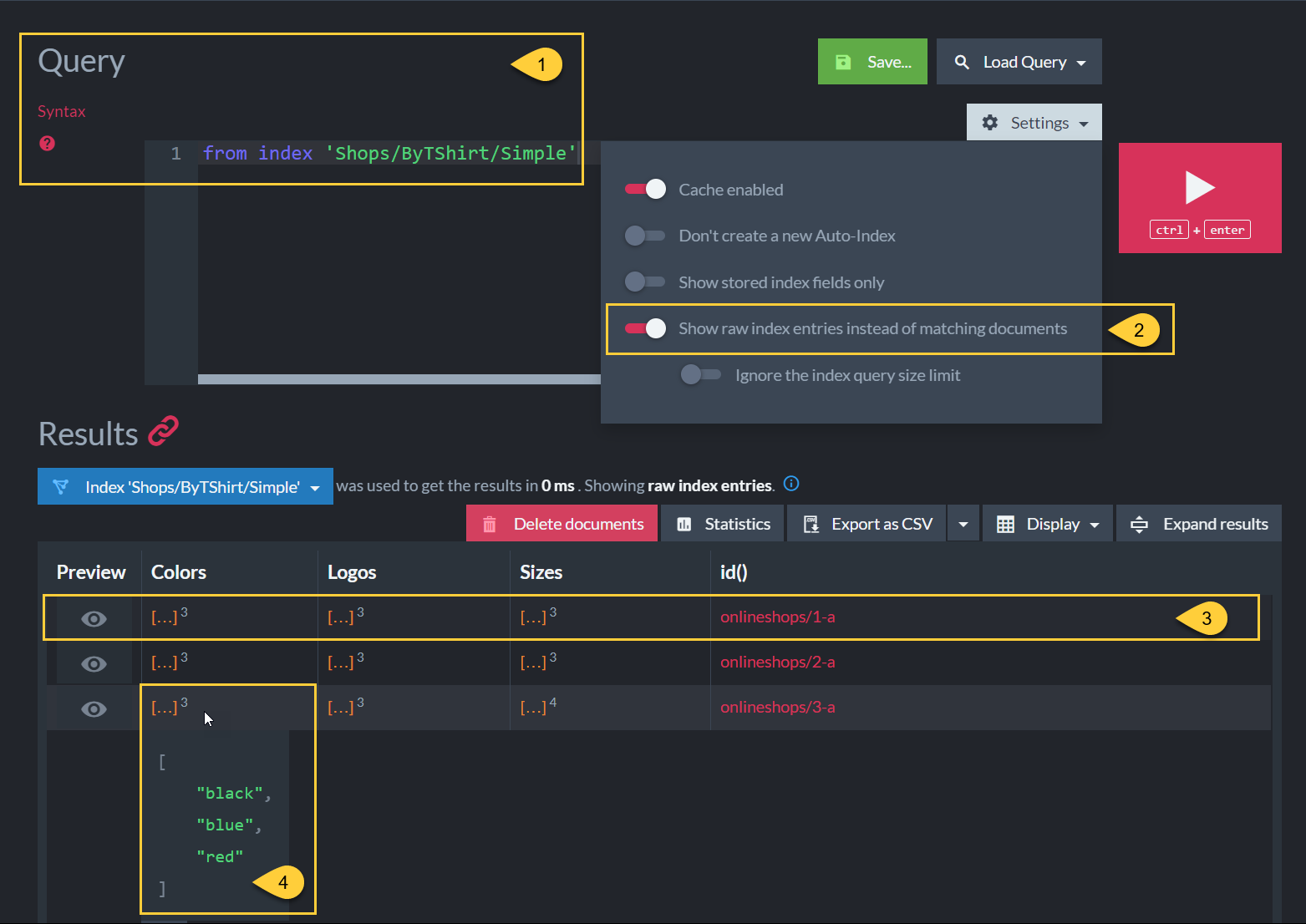
The index-entries content is visible from the Studio Query view.
-
Check option: Show raw index-entries instead of Matching documents.
-
Each row represents an index-entry.
The index has a single index-entry per document (3 entries in this example). -
The index-field contains a collection of ALL nested values from the document.
e.g. The third index-entry has the following values in the Colors index-field:
{"black", "blue", "red"}
-
- Query
- Query_async
- DocumentQuery
- RQL
// Query for all shop documents that have a red TShirt
var shopsThatHaveRedShirts = session
.Query<Shops_ByTShirt_Simple.IndexEntry, Shops_ByTShirt_Simple>()
// Filter query results by a nested value
.Where(x => x.Colors.Contains("red"))
.OfType<OnlineShop>()
.ToList();
// Query for all shop documents that have a red TShirt
var shopsThatHaveRedShirts = await asyncSession
.Query<Shops_ByTShirt_Simple.IndexEntry, Shops_ByTShirt_Simple>()
// Filter query results by a nested value
.Where(x => x.Colors.Contains("red"))
.OfType<OnlineShop>()
.ToListAsync();
// Query for all shop documents that have a red TShirt
var shopsThatHaveRedShirts = session.Advanced
.DocumentQuery<Shops_ByTShirt_Simple.IndexEntry, Shops_ByTShirt_Simple>()
// Filter query results by a nested value
.ContainsAny(x => x.Colors, new[] { "Red" })
.OfType<OnlineShop>()
.ToList();
from index "Shops/ByTShirt/Simple"
where Colors == "red"
// Results will include the following shop documents:
// ==================================================
// * Shop1
// * Shop3
-
-
This type of index structure is effective for retrieving documents when filtering the query by any of the inner nested values that were indexed.
-
However, due to the way the index-entries are generated, this index cannot provide results for a query searching for documents that contain specific sub-objects which satisfy some
ANDcondition.
For example:
-
// You want to query for shops containing "Large Green TShirts",
// aiming to get only "Shop1" as a result since it has such a combination,
// so you attempt this query:
var GreenAndLarge = session
.Query<Shops_ByTShirt_Simple.IndexEntry, Shops_ByTShirt_Simple>()
.Where(x => x.Colors.Contains("green") && x.Sizes.Contains("L"))
.OfType<OnlineShop>()
.ToList();
// But, the results of this query will include BOTH "Shop1" & "Shop2"
// since the index-entries do not keep the original sub-objects structure.
- To address this, you must use a Fanout index - as described below.
Fanout index - Multiple index-entries per document
-
-
A fanout index is an index that outputs multiple index-entries per document.
A separate index-entry is created for each nested sub-object from the document. -
The fanout index is useful when you need to retrieve documents matching query criteria
that search for specific sub-objects that comply with some logical conditions.
-
- LINQ_index
- JavaScript_index
// A fanout map-index:
// ===================
public class Shops_ByTShirt_Fanout : AbstractIndexCreationTask<OnlineShop>
{
public class IndexEntry
{
// The index-fields:
public string Color { get; set; }
public string Size { get; set; }
public string Logo { get; set; }
}
public Shops_ByTShirt_Fanout()
{
Map = shops =>
from shop in shops
from shirt in shop.TShirts
// Creating MULTIPLE index-entries per document,
// an index-entry for each sub-object in the TShirts list
select new IndexEntry
{
Color = shirt.Color,
Size = shirt.Size,
Logo = shirt.Logo
};
}
}
public class Shops_ByTShirt_JS : AbstractJavaScriptIndexCreationTask
{
public Shops_ByTShirt_JS()
{
Maps = new HashSet<string>
{
@"map('OnlineShops', function (shop){
var res = [];
shop.TShirts.forEach(shirt => {
res.push({
Color: shirt.Color,
Size: shirt.Size,
Logo: shirt.Logo
})
});
return res;
})"
};
}
}
- Query
- Query_async
- DocumentQuery
- RQL
// Query the fanout index:
// =======================
var shopsThatHaveMediumRedShirts = session
.Query<Shops_ByTShirt_Fanout.IndexEntry, Shops_ByTShirt_Fanout>()
// Query for documents that have a "Medium Red TShirt"
.Where(x => x.Color == "red" && x.Size == "M")
.OfType<OnlineShop>()
.ToList();
// Query the fanout index:
// =======================
var shopsThatHaveMediumRedShirts = await asyncSession
.Query<Shops_ByTShirt_Fanout.IndexEntry, Shops_ByTShirt_Fanout>()
// Query for documents that have a "Medium Red TShirt"
.Where(x => x.Color == "red" && x.Size == "M")
.OfType<OnlineShop>()
.ToListAsync();
// Query the fanout index:
// =======================
var shopsThatHaveMediumRedShirts = session.Advanced
.DocumentQuery<Shops_ByTShirt_Fanout.IndexEntry, Shops_ByTShirt_Fanout>()
// Query for documents that have a "Medium Red TShirt"
.WhereEquals(x => x.Color, "red")
.AndAlso()
.WhereEquals(x=> x.Size, "M")
.OfType<OnlineShop>()
.ToList();
from index "Shops/ByTShirt/Fanout"
where Color == "red" and Size == "M"
// Query results:
// ==============
// Only the 'Shop1' document will be returned,
// since it is the only document that has the requested combination within the TShirt list.
-
-
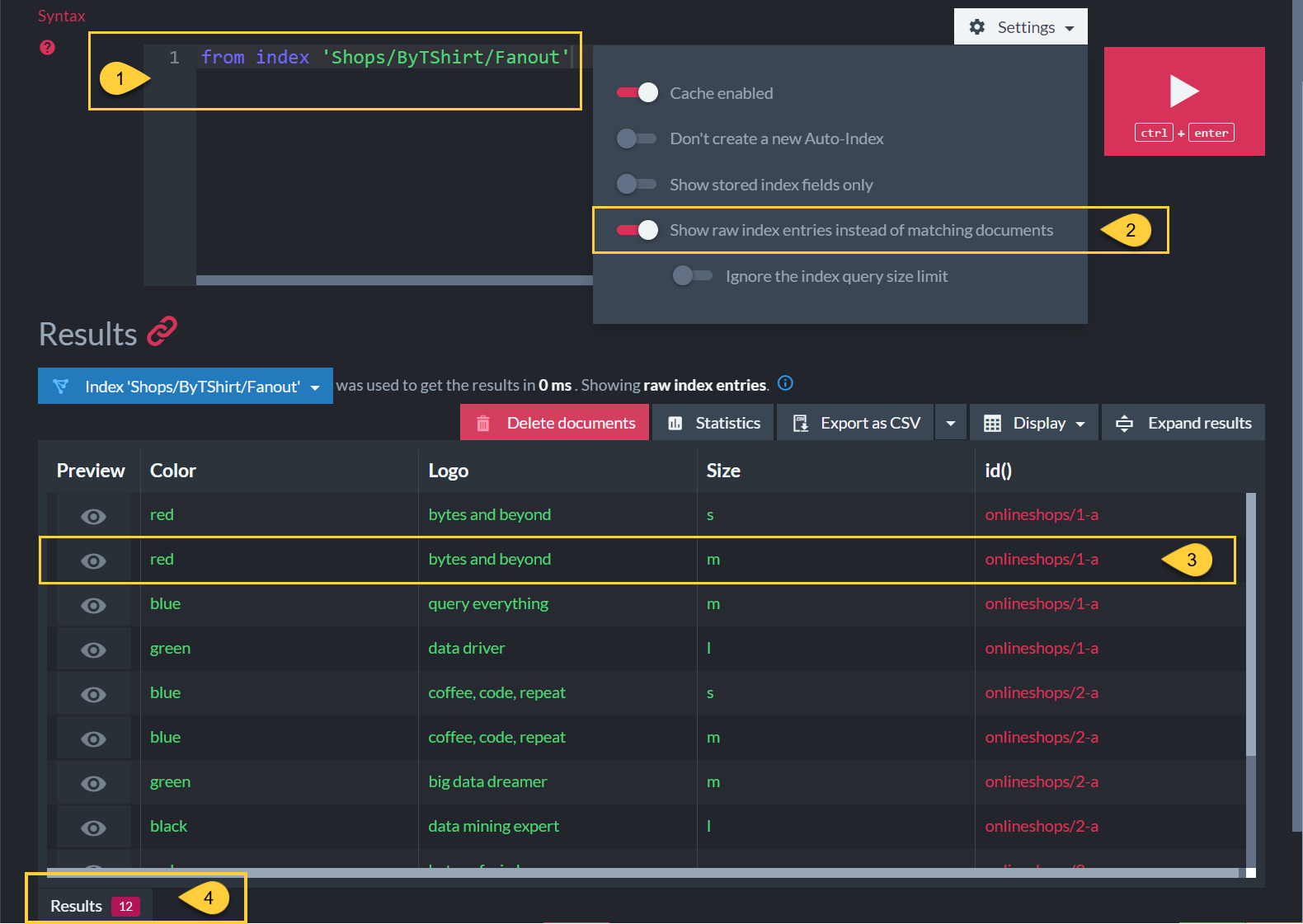
The index-entries content is visible from the Studio Query view.
-
Check option: Show raw index-entries instead of Matching documents.
-
Each row represents an index-entry.
Each index-entry corresponds to an inner item in the TShirt list. -
In this example, the total number of index-entries is 12,
which is the total number of inner items in the TShirt list in all 3 documents in the collection.
-
-
Fanout index - Map-Reduce index example:
- The fanout index concept applies to map-reduce indexes as well:
- LINQ_index
- JavaScript_index
// A fanout map-reduce index:
// ==========================
public class Sales_ByTShirtColor_Fanout :
AbstractIndexCreationTask<OnlineShop, Sales_ByTShirtColor_Fanout.IndexEntry>
{
public class IndexEntry
{
// The index-fields:
public string Color { get; set; }
public int ItemsSold { get; set; }
public decimal TotalSales { get; set; }
}
public Sales_ByTShirtColor_Fanout()
{
Map = shops =>
from shop in shops
from shirt in shop.TShirts
// Creating MULTIPLE index-entries per document,
// an index-entry for each sub-object in the TShirts list
select new IndexEntry
{
Color = shirt.Color,
ItemsSold = shirt.Sold,
TotalSales = shirt.Price * shirt.Sold
};
Reduce = results => from result in results
group result by result.Color
into g
select new
{
// Calculate sales per color
Color = g.Key,
ItemsSold = g.Sum(x => x.ItemsSold),
TotalSales = g.Sum(x => x.TotalSales)
};
}
}
public class Product_Sales : AbstractJavaScriptIndexCreationTask
{
public class Result
{
public string Product { get; set; }
public int Count { get; set; }
public decimal Total { get; set; }
}
public Product_Sales()
{
Maps = new HashSet<string>()
{
@"map('orders', function(order){
var res = [];
order.Lines.forEach(l => {
res.push({
Product: l.Product,
Count: 1,
Total: (l.Quantity * l.PricePerUnit) * (1- l.Discount)
})
});
return res;
})"
};
Reduce = @"groupBy(x => x.Product)
.aggregate(g => {
return {
Product : g.key,
Count: g.values.reduce((sum, x) => x.Count + sum, 0),
Total: g.values.reduce((sum, x) => x.Total + sum, 0)
}
})";
}
}
- Query
- Query_async
- DocumentQuery
- RQL
// Query the fanout index:
// =======================
var queryResult = session
.Query<Sales_ByTShirtColor_Fanout.IndexEntry, Sales_ByTShirtColor_Fanout>()
// Query for index-entries that contain "black"
.Where(x => x.Color == "black")
.FirstOrDefault();
// Get total sales for black TShirts
var blackShirtsSales = queryResult?.TotalSales ?? 0;
// Query the fanout index:
// =======================
var queryResult = await asyncSession
.Query<Sales_ByTShirtColor_Fanout.IndexEntry, Sales_ByTShirtColor_Fanout>()
// Query for index-entries that contain "black"
.Where(x => x.Color == "black")
.FirstOrDefaultAsync();
// Get total sales for black TShirts
var blackShirtsSales = queryResult?.TotalSales ?? 0;
// Query the fanout index:
// =======================
var queryResult = session.Advanced
.DocumentQuery<Sales_ByTShirtColor_Fanout.IndexEntry, Sales_ByTShirtColor_Fanout>()
// Query for index-entries that contain "black"
.WhereEquals(x => x.Color, "black")
.FirstOrDefault();
// Get total sales for black TShirts
var blackShirtsSales = queryResult?.TotalSales ?? 0;
from index "Sales/ByTShirtColor/Fanout"
where Color == "black"
// Query results:
// ==============
// With the sample data used in this article,
// The total sales revenue from black TShirts sold (in all shops) is 490.0
-
Fanout index - Performance hints:
-
Fanout indexes are typically more resource-intensive than other indexes as RavenDB has to index a large number of index-entries. This increased workload can lead to higher CPU and memory utilization, potentially causing a decline in the overall performance of the index.
-
When the number of index-entries generated from a single document exceeds a configurable limit,
RavenDB will issue a High indexing fanout ratio alert in the Studio notification center. -
You can control when this performance hint is created by setting the PerformanceHints.Indexing.MaxIndexOutputsPerDocument configuration key (default is 1024).
-
So, for example, adding another OnlineShop document with a
tShirtobject containing 1025 items
will trigger the following alert: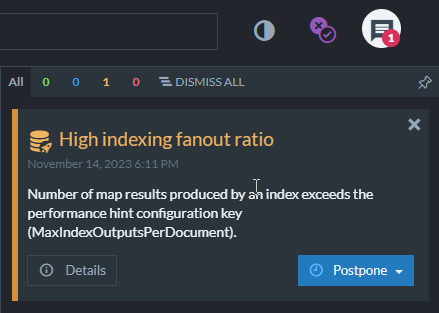
-
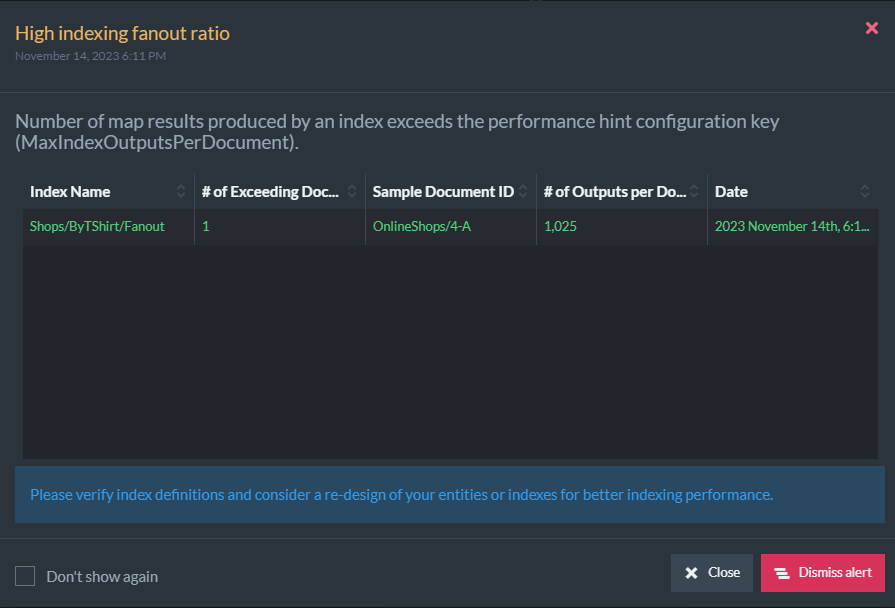
Clicking the 'Details' button will show the following info:
-
-
-
A fanout index has more index-entries than the number of documents in the collection indexed.
Multiple index-entries "point" to the same document from which they originated,
as can be seen in the above index-entries example. -
When making a fanout index query that should return full documents (without projecting results),
then in this case, theTotalResultsproperty (available via theQueryStatisticsobject) will contain
the total number of index-entries and Not the total number of resulting documents. -
To overcome this when paging results, you must take into account the number of "duplicate"
index-entries that are skipped internally by the server when serving the resulting documents. -
Please refer to paging through tampered results for further explanation and examples.
-